


A real world project using Python Statsmodels to display model estimation process of linear regression model
In the previous posts, we have talked about how to preprocess the datasets, mainly includes data cleaning, data encoding, data splitting and data normalization. As for data cleaning, we talked about column rename, missing values detection, missing value imputation, outliers detection and their treatment. In this article, we will discuss the process how to develop a classical statistic linear regression models with Statsmodels library.
It is usually boring to write and read one long post, so I would like to divide this topic into the following parts:
Part I: Model Estimation
Part II: Model Diagnostics
Part III: Model Improvement
Part IV: Model Evaluation
This article is the first part. In this part, let’s start from reading the encoded dataset, gdp_china_encoded.csv, a real-world dataset. If you read my previous posts and followed me, you might have this preprocessed dataset. Otherwise, you can download it from my GitHub repository by click this link.
1. Import the required packages
First, let’s import the required packages.
import pandas as pd
from sklearn.model_selection import train_test_split
import statsmodels.api as sm
2. Read the data
Then read the data from your working directory. You can also read the data directly from the GitHub, you can read the previous post to see how to do it.
df = pd.read_csv('./data/gdp_china_encoded.csv',index_col=False)
df.head()
You can glance over this post to understand what the column names stand for.
3. Define independent variables (X) and dependent variable (y)
I have talked about feature selection in the previous post in details, in which we choose GDP as the dependent variable (y) and others as the independent variables (X). In this case, we will establish a multiple linear regression model because there are multiple independent variables.
X = df.drop(['gdp'],axis=1)
y = df['gdp']
4. Split the dataset
We split the dataset into two parts: 70% for model estimation/fitting and 30% for model validation. You can read this post for dataset splitting.
X_train, X_test, y_train, y_test = train_test_split(X, y,test_size=0.30, random_state=1)
5. Data normalization in statistical regression (optional)
For a multiple linear regression model, it is widely accepted that it is not necessary to normalize the data. Statistical linear regression stress explanatory model, the estimated coefficients describe the relation between independent variables and dependent variable.
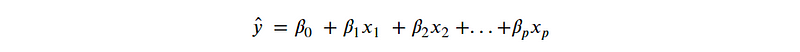
The regression coefficient ????₁ is interpreted as the expected change in ŷ associated with a 1-unit increase/decrease in ????₁ while ????₂, …, ????ₚ are held fixed.
I suggest using decimal scaling normalization method, and it will be helpful. Here we will just see the process on how to develop a classical statistic regression model, so we will not normalize independent variable here. In the future, I will write a post to compare if there is different between normalization and non-normalization.
6. Model estimation
Model estimation or model fit is a general term denoting the precise quantitative procedure, by which a quantitative model is developed. More specifically, model fit or model estimation is the methodology by which the model parameters are derived. Model training/training a model is a modern term from a machine learning perspective, which is also widely used nowadays.
Ordinary least squares (OLS) is usually used in a linear regression model, which is a type of linear least squares method for estimating the unknown parameters. We will use statsmodels.api, and we already imported it at the very beginning.
# add a constant
X_train = sm.add_constant(X_train)
# define the model and fit it
model = sm.OLS(y_train, X_train)
results = model.fit()
Let’s display the model result.
results.summary()
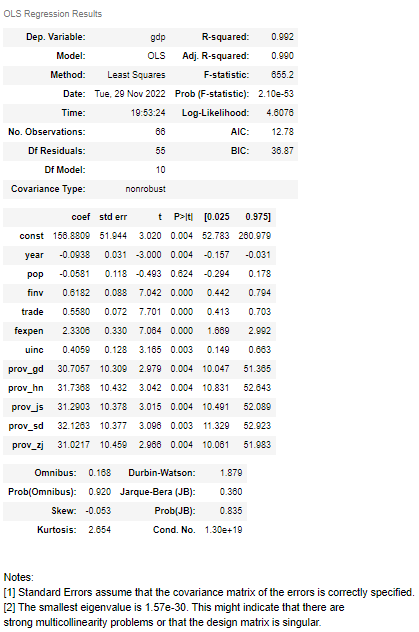
So far, we get the above summary of the model results.
How to interpret these results?
Is this model good?
We will discuss these questions in the next post. How to diagnose the model?
7. Online Course
If you are interested in learning Python data analysis in details, you are welcome to enroll one of my courses:
Master Python Data Analysis and Modelling Essentials