


Split dataset is an important step of data preprocessing for a reliable model
In the last post, it briefly discussed the main concepts on data analysis and modelling. This article will continue to discuss how to split a dataset for developing a model. Data splitting is an important component of data preprocessing in model development.
We will use the dataset of gdp_china_encoded.csv, which is a cleaned and encoded dataset that was processed in some previous articles. You can directly download this cleaned and encoded dataset from my GitHub repository by click this link. But I suggest you reading the related articles in order to better understand what the raw dataset looks like and how this cleaned and encoded dateset was obtained from the raw dataset.
1. Read Dataset
# import required package(s)
import pandas as pd
# read data
df = pd.read_csv('./data/gdp_china_encoded.csv')
# didplay the Dataframe
df
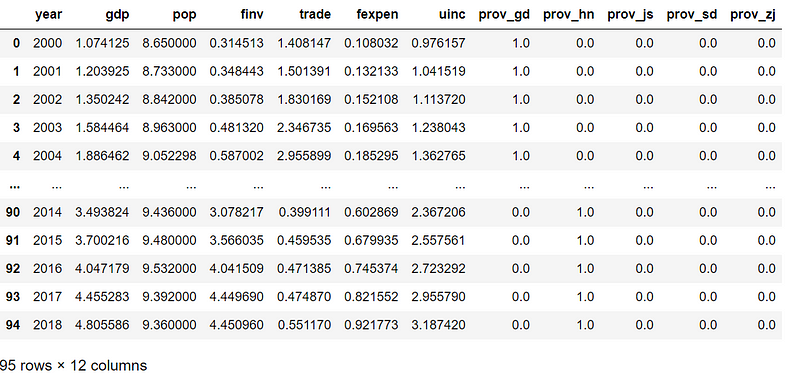
where:
- gdp: GDP (x10⁸CNY)
- pop: Total population (x10⁴ person)
- finv: Fixed assets investment (x10⁸ CNY)
- trade: Total imports and exports (CNY)
- fexpen: Fiscal expenditure (x10⁹CNY)
- uinc: Urban disposal income per capita (CNY)
- prov_gd: Guandong Province
- prov_hn: Henan Province
- prov_js: Jiangsu Province
- prov_sd: Shandong Province
- prov_zj: Zhejiang Pronvice
1. Slice data into features X and target y
X: also called independent variables, the predictors, explanatory, treatment variables, factors, input variables, x-variables, or right-hand variables (because they appear on the right side of the regression equation)y: also called dependent variable, the response, outcome variable, y-variable, or left-hand variable
From the results of correlation analysis, we already know that there are higher linear correlation between variables. Hence, the final objective is to develop a GDP linear regression model using the other variables, so y is GDP and X is all the other variables. Let’s slice y and X from the dataset.
X = df.drop(['gdp'],axis=1)
y = df['gdp']
# show the feature variable
X
# display the target variable
y

2. Split Train and Test Set
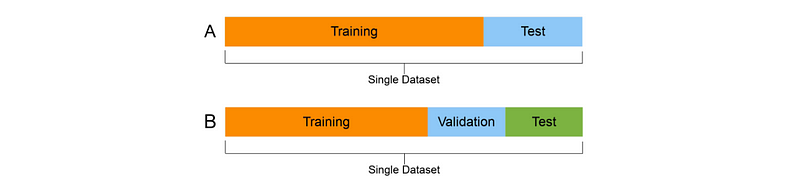
For statistic regression model, a dataset is normally split into two parts. In machine learning, they are usually called training dataset and testing dataset. In classical statistic modelling, they are typically called estimation dataset and validation or testing dataset. However, nowadays, people typically generally called training set and testing set.
For a strict machine learning model, especially deep learning model, a dateset is typically split into 3 parts: Training, Validation and Test.
Here we only need to spit the dataset into two parts because our goal is to establish a linear regression model based on our data in the next step.
The Python Scikit-learn library provides a very convenient method to split the data. We can use it to split the dataset as follows.
# import the train_test_split function
from sklearn.model_selection import train_test_split
# split the dataset
X_train, X_test, y_train, y_test = train_test_split(X,y,test_size=0.30,random_state=1)
# display training set, for example
X_train
The first few lines of the result looks as follows:

# show the shape of training X set
X_train.shape
Out[32]: (66, 10)
# show the shape of testing X set
X_test.shape
Out[34]: (29, 10)
3. Online course
If you are interested in learning essential of Python data analysis and modelling in details, you are welcome to enroll one of my courses:
Master Python Data Analysis and Modelling Essentials