


To normalize dataset is another important step of data preprocessing in model development
The last article discussed how to split the dataset into feature variables and target variable using Scikit-learn library in Python. Data normalization is another important component of data preprocessing in modelling. In this article, I will discuss different methods to normalize the features.
1. Normalization and Standardization
The terms standardize and normalize are interchangeably used in data preprocessing, although the term of normalization has a range of connotations in statistics and applied statistics.
The process of normalization involves transforming the data to a smaller or common range, such as [−1,1] or [0, 1].
2. Why data normalization?
The main benefits of data normalization, including:
- gives all attributes an equal weight
- avoids dependence on the measurement units
- particularly useful for machine learning training or
- helps speed up the learning phase
In a linear regression model, it can help too, though it is not necessary.
3. Methods for data normalization
(1) Min-max normalization
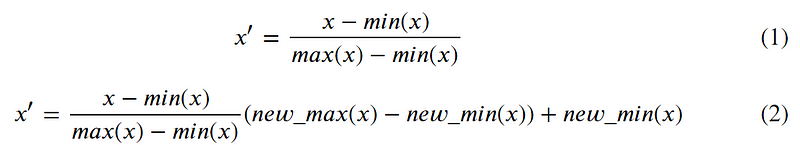
(2) Mean normalization
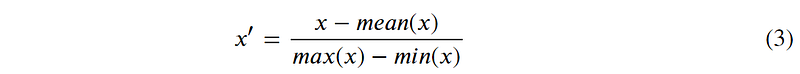
(3) Z-score normalization / Standardization
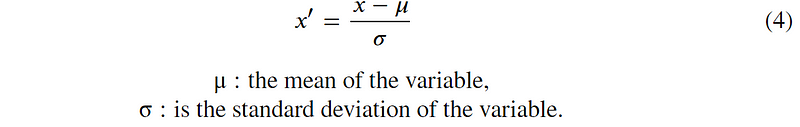
(5) Scaling to unit length
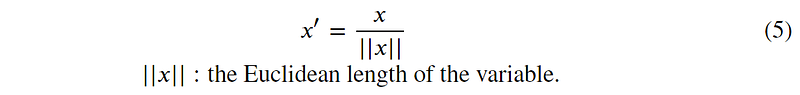
(6) Decimal scaling
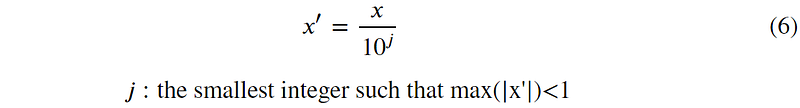
2. Built-in Normalization Methods in Scikit-learn
- MinMaxScaler: Transform features by scaling each feature to a given range
- MaxAbsScaler: Scale each feature by its maximum absolute value [-1, 1] by dividing through the largest maximum value
- RobustScaler: Scale features using statistics that are robust to outliers. It subtracts the column median and divides by the interquartile range.
- StandardScaler: StandardScaler scales each column to have 0 mean and unit variance.
- Normalizer: Normalize samples individually to unit norm. The normalizer operates on the rows rather than the columns. It applies l2 normalization by default.
If you want to learn more in details, please go to the official online document of Scikit-learn.
3. Normalization Example
Let’s see how to apply these built-in methods using the dataset, gdp_china_encoded.csv used in the previous article.
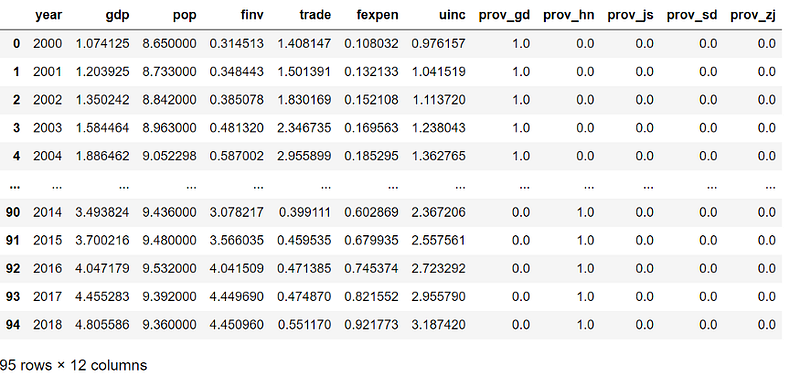
(1) Read Dataset
# import required packages
import pandas as pd
# read data
df = pd.read_csv('./data/gdp_china_encoded.csv')
# didplay the Dataframe
df
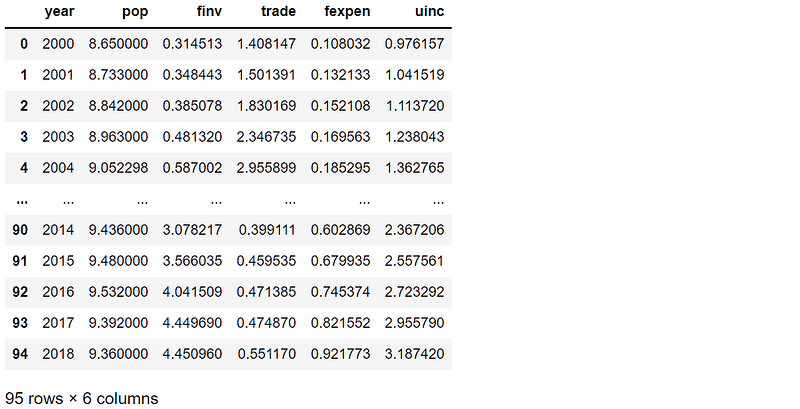
(2) Select the columns to normalize
For data normalization, we only need to normalize the features. In the last article, we have already displayed how to select the feature dataset.
The five province dummy variables are already in the range [0,1], thus it does not need to normalize them.
# select the features
X = df.drop([‘gdp’],axis=1)
# select the data need to normalize
X1 = X.loc[:,'year':'uinc']
(3) Import the normalization scaler
We need to import the normalization scaler from sklearn.preprocessing the module. For example, we will use theMinMaxScaler method, so we import it.
from sklearn.preprocessing import MinMaxScaler
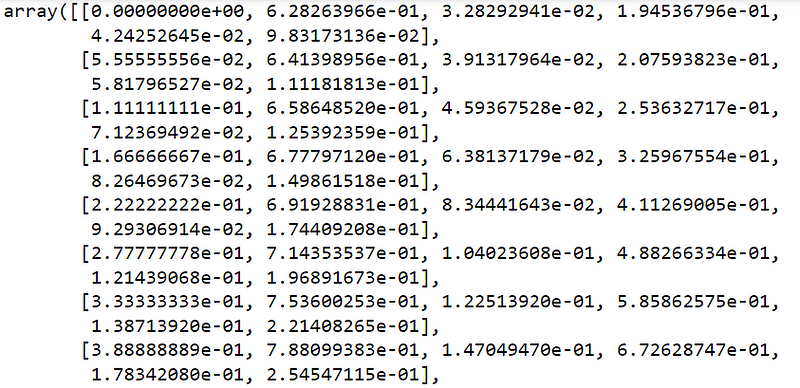
(4) Normalize the selected data
# to learn the underlying parameters of the scaler from the training data-set
min_max_scaler = MinMaxScaler().fit(X1)
# transform the training data-set to range [0,1]
X1_scaled = min_max_scaler.transform(X1)
# diplayed the normalized date
X1_scaled
The first few lines look as follows:
It is NumPy array, and we transfer it to Pandas DataFrame.
X1_scaled = pd.DataFrame(X1_scaled,index=X1.index,columns=X1.columns)
X1_scaled
4. Online course
If you are interested in learning essentials of Python data analysis and modelling in details, you are welcome to enroll one of my courses:
Master Python Data Analysis and Modelling Essentials