


Discuss the widely used improper data normalization process, and display the proper procedure using a real-world dataset
The last two articles discussed how to split dataset and different data normalization methods. What is the right procedure, splitting data first or normalizing data first? In this article, the proper data normalization procedure will be displayed using the real-world dataset, which have been used in the previous articles.
1. Improper Data Normalization Concepts
(1) Incorrect Split-Normalization Order
The widely applied method is that the whole dataset is normalized as I did in the example in the last article, and then the normalized data is split into training dataset and testing dataset. This procedure is not proper, or wrong, which might result in unbelievable model and model results.
Why is it not proper, or even wrong, to normalize data first and then split it into training dataset and testing dataset? Let’s think what the training dataset and testing dataset are used for. In general, the training set is used for developing the model, while the testing set is used for testing the prediction accuracy of the developed model. Thus, testing dataset works as the new dataset that has not been used in creating the model. We can regard it as newly collected dataset to test if the model can predict these newly collected dataset. In this sense, it is not hard to understand that we should not normalize the whole dataset first and then split it.
(2) Inconsistent scalers for training set and test set
The second widely used wrong procedure is that the training dataset and testing dataset are normalized with different normalization scalers, i.e. training scaler and testing scaler, respectively.
(3) Wrongly Normalized Dummy or Encoded Variables
The third used wrong procedure that some people might use is that the dummy or encoded string variables in a dataset, as the dataset used in this article and the previous several articles.
(4) Unnecessary Normalization of Target variable
For data normalization for modelling, many people normalize both feature and target variables. It is really unnecessary to normalize the target variable. One of the important reasons for normalization is to give all attributes an equal weight, and the main reasons for data normalization have already been discussed in the post.
Let’s use some concrete examples to display the proper normalization process, then you will understand much better what I meant.
2. Normalization Process for Training Dataset
I will divide the process into the following steps.
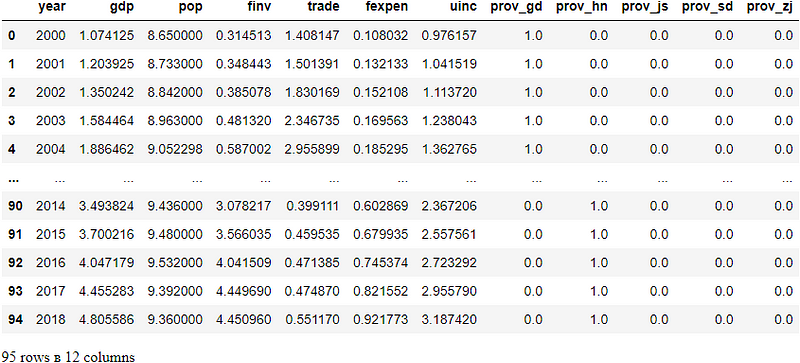
Step 1: Read the Dataset
We still use the gdp_china_encoded.csv that we used in previous posts. I suggest you reading them in order to better understand the whole process on data preprocessing if you are the first time to read my post. If you are interested in this tutorial article, you can download this dataset from my GitHub repository by click this link.
# we need panadas to import required packages
import pandas as pd
# read data
df = pd.read_csv('./data/gdp_china_encoded.csv')
# show the first 5 rows
df
Step 2: Split Dataset
As above discussed, the correct procedure is to split the dataset before normalization. The splitting methods have been discussed in the previous article.
(1) Split Features X and Target y
X = df.drop(['gdp'],axis=1)
y = df['gdp']
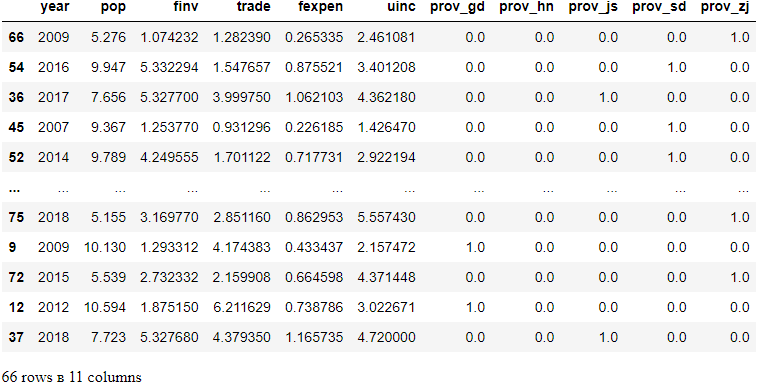
(2) Split Training and Testing data
We use train_test_splitof Scikit-learn to split the dataset into training set and test set. So we need to import the function first.
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y,test_size=0.30, random_state=1)
X_train
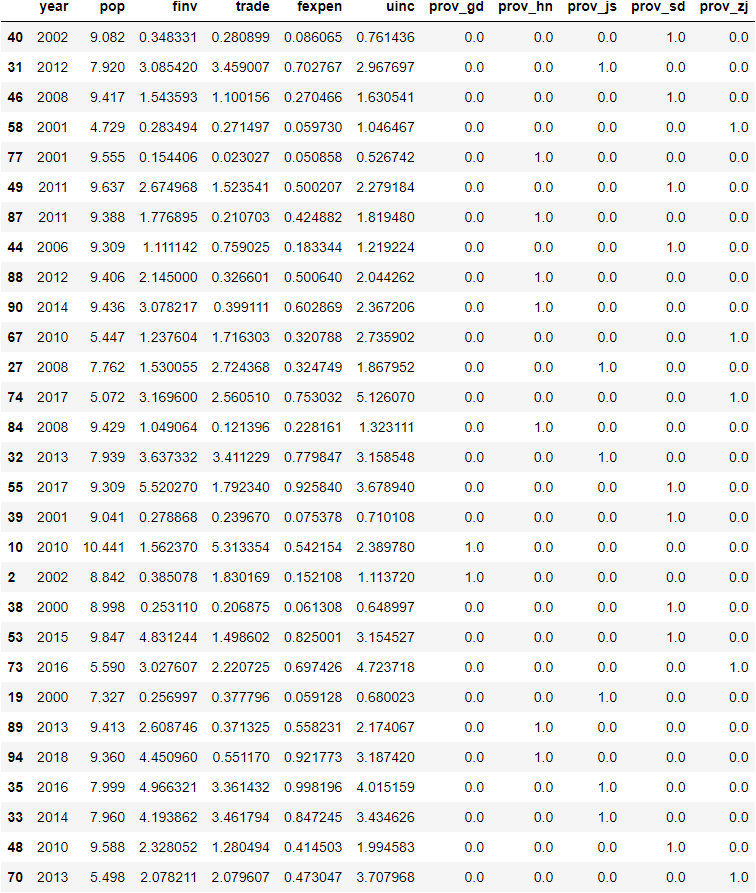
X_test
Step 3: Select the Variable Needed to Normalize
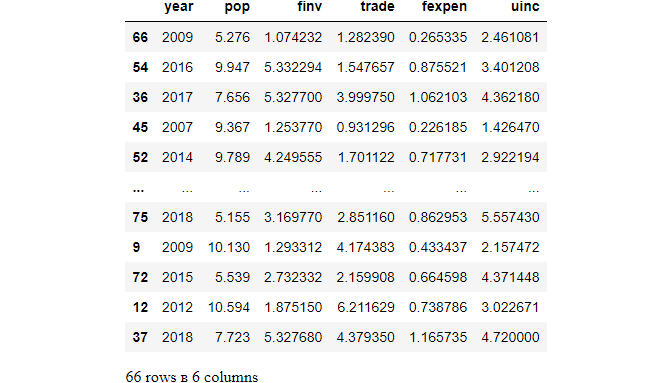
In this example, the encoded or dummy variables are not needed to normalize because they are already in the range of [0,1]. We have talked about the reasons in the previous post.
X1_train = X_train.loc[:,'year':'uinc']
X1_train
Step 4: Normalize the Training Feature Data
As we discussed in section 1, it only needs to normalize the training feature data. In this example, we use MinMaxScaler method in the Scikit-learn library.
(1) Import the Module
from sklearn.preprocessing import MinMaxScaler
(2) Create the training scaler
# to learn the underlying parameters of the scaler from the training data-set
min_max_scaler = MinMaxScaler().fit(X1_train)
(3) Normalize the training dataset
# transform the training data-set to range [0,1]
X1_train_scaled = min_max_scaler.transform(X1_train)
X1_train_scaled
The first few lines of the output as follows:
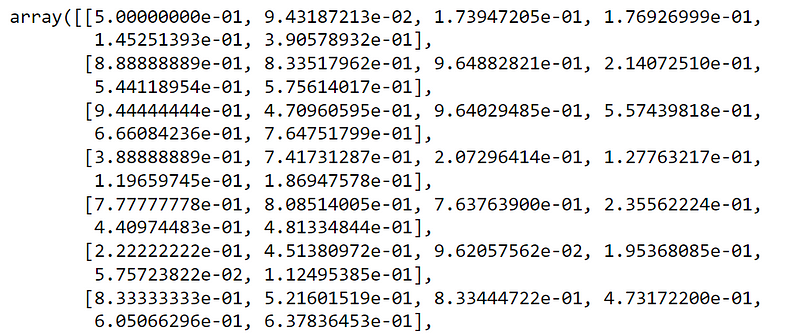
(3) Convert it into DataFrame
This is not necessary, but if you are interested in displaying it in DataFrame of Pandas, just do it as follows:
X1_train_scaled = pd.DataFrame(X1_train_scaled,index=X1_train.index,columns=X1_train.columns)
X1_train_scaled
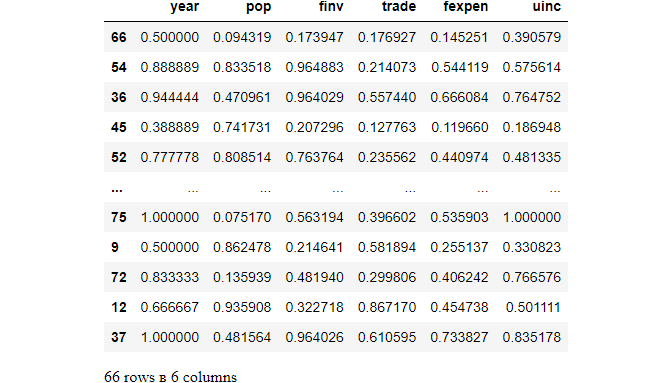
(4) Display the full scaled train dataset
There are many methods to combine the scaled training dataset with encoded training variables. Here, I use the following methods.
X_train_scaled = X_train.copy()
X_train_scaled.loc[:,'year':'uinc'] = X1_train_scaled
X_train_scaled
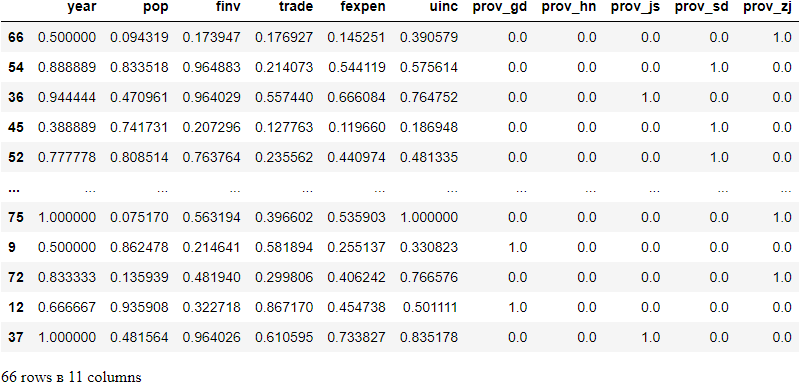
(5) Save the training scaler
let’s save the training scaler named with mm_scaler for future use.
import joblib
joblib.dump(min_max_scaler,'mm_scaler')
[‘mm_scaler’]
3. Normalization Process for Testing Dataset
Suppose we have developed a model, the next step is to test the model using the test model. The process is similar with training dataset normalization except few steps. I will divide the process into the following steps.
Step 1: Select the Variable Needed to Normalize
X1_test = X_test.loc[:,'year':'uinc']
X1_test
Step 2: Normalize the Test Feature Data
We already import the all the packages and functions we need during the training process. If you use a separate file, you need to import them again.
Remember as we discussed in the section 1, testing dataset normalization should use the same scaler, with training dataset.
Method 1
Since training data and testing datasets normalization are in the same file, we can use the training scaler directly for testing data normalization.
# use the train scaler directly
# transform the training data-set to range [0,1]
X1_test_scaled = min_max_scaler.transform(X1_test)
X1_test_scaled
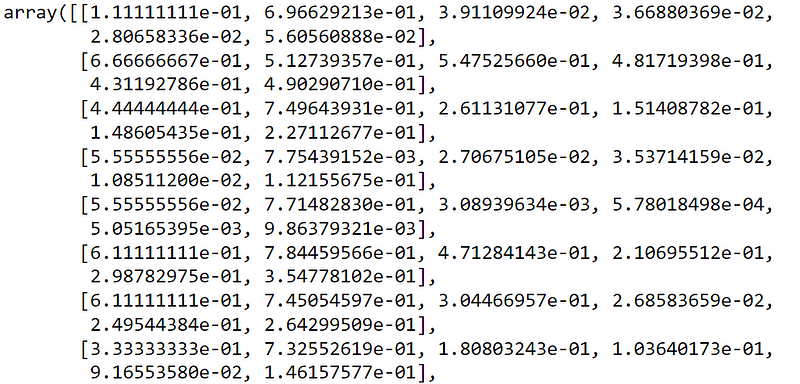
Just few lines of the results.
Method 2: import the train scaler
We load the saved train scaler at the end of the training dataset normalization.
# import joblib
min_max_scaler = joblib.load('mm_scaler')
X1_test_scaled = min_max_scaler.transform(X1_test)
X1_test_scaled
We get the same results as above.
Step 3: Convert it into DataFrame
Similarly, if you are interested in displaying it in DataFrame of Pandas, just do it as follows:
X1_test_scaled = pd.DataFrame(X1_test_scaled,index=X1_test.index,columns=X1_test.columns)
X1_test_scaled

Step 4: Display the Full Scaled Test Dataset
X_test_scaled = X_test.copy()
X_test_scaled.loc[:,'year':'uinc'] = X1_test_scaled
X_test_scaled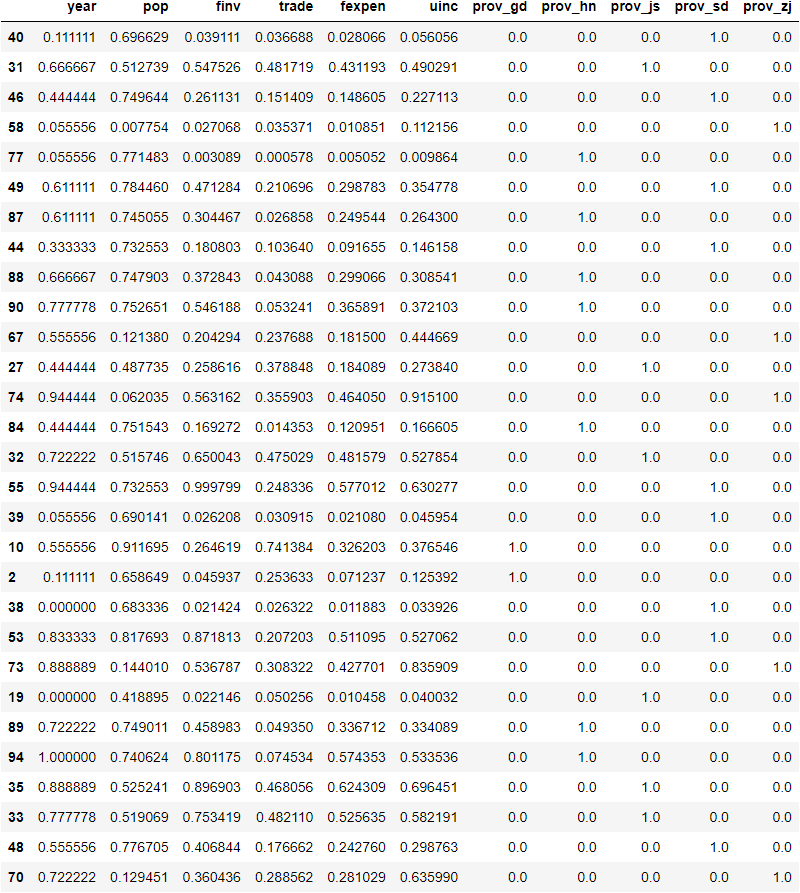
4. Online course
If you are interested in learning essential of Python data analysis and modelling in details, you are welcome to enroll one of my courses:
Master Python Data Analysis and Modelling Essentials