

Manipulating string data is crucial in many data analysis tasks with Pandas
Pandas is a powerful data manipulation library in Python that offers various functions and methods to work with structured data. While it excels in handling numerical and tabular data, it also provides robust support for string data. Manipulating string data is crucial in many data analysis tasks, such as cleaning messy text, extracting information, and transforming strings into more meaningful representations.
This tutorial aims to introduce you to the fundamentals of working with string data using Pandas. We will cover key operations, methods, and techniques to manipulate, analyze, and transform string data effectively. By the end of this tutorial, you will have a solid understanding of how to leverage Pandas to handle string data in your data analysis projects.
1. Creating a DataFrame with String Data
In this section, we will explore how to create a Pandas DataFrame containing string data and understand the various ways to import string data from different sources.
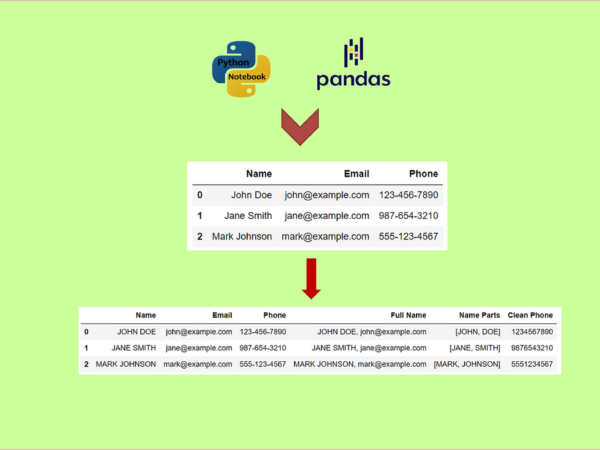
import pandas as pd
data = {'Name': ['John Doe', 'Jane Smith', 'Mark Johnson'],
'Email': ['john@example.com', 'jane@example.com', 'mark@example.com'],
'Phone': ['123-456-7890', '987-654-3210', '555-123-4567']}
df = pd.DataFrame(data)
df
2. Accessing and Modifying String Columns
Here, we will learn how to access and modify specific string columns in a DataFrame, including slicing, indexing, and applying functions to transform the string values.
Example 1: Accessing a specific string column
names = df['Name']
names
Example 2: Modifying a string column
df['Name'] = df['Name'].str.upper()
df
3. String Operations and Methods
This section covers a wide range of common string operations and methods in Pandas, such as concatenation, splitting, stripping, substitution, matching, filtering, case conversion, and computing string length and counts.
Example 1: String Concatenation
df['Full Name'] = df['Name'].str.cat(df['Email'], sep=', ')
df
Example 2: String Splitting
df['Name Parts'] = df['Name'].str.split()
df
Example 3: String Substitution
df['Clean Phone'] = df['Phone'].str.replace('-', '')
df
Example 4: String Matching and Filtering
filtered_df = df[df['Email'].str.contains('mark')]
filtered_df
Example 5: Case Conversion
df['Name'] = df['Name'].str.lower()
df
Example 6: String Length and Count
df['Name Length'] = df['Name'].str.len()
df['Name Vowel Count'] = df['Name'].str.count('[aeiou]')
df
4. Conditional String Operations
We will dive into performing conditional string operations based on certain criteria, including conditional replacement, filtering, and extracting specific patterns from string columns.
Example 1: Conditional Replacement
df.loc[df['Name'].str.contains('john', case=False), 'Name'] = 'John Smith'
df
Example 2: Conditional Filtering
filtered_df = df[df[‘Name’].str.startswith(‘J’)]
filtered_df
Example 3: Conditional String Extraction
df[‘First Initial’] = df[‘Name’].str.extract(r’^(\w)’, expand=False)
df
5. String Data Cleaning and Preprocessing
Cleaning and preprocessing text data are essential steps in any data analysis task. In this section, we will explore techniques to handle missing values, remove special characters, convert strings to lowercase, and perform other common text cleaning operations.
First, we create another string DataFrame with Pandas.import pandas as pd
# Creating a DataFrame with missing values in a string column
data = {'Name': ['John Doe$', 'Jane Smith', None, 'Mark Johnson%'],
'Email': ['john@example.com', 'jane@example.com', 'mark@example.com', None]}
df = pd.DataFrame(data)
df
Example 1: Handling Missing Values
In this example, we will handle missing values by replacing them with specified values.
df['Name'].fillna('Unknown', inplace=True)
df['Email'].fillna('unknown@example.com', inplace=True)
df
Example 2: Removing Special Characters
Let’s remove special characters from string columns.
df[‘Name’] = df[‘Name’].str.replace(‘[#,$,&,%]’, ‘’,regex=True)
df
In this example, it removes all characters in ‘Name’ column that contains #,$,&,%.
6. Advanced String Operations
This section introduces advanced string operations using regular expressions with Pandas. We will cover regex-based string extraction and replacement techniques to tackle complex string patterns.
Example 1: Regular Expressions with Pandas
We create another string DataFrame to display the methods.
import pandas as pd
# Creating a DataFrame with string data
data = {'Text': ['apple', 'banana', 'orange', 'grapefruit', 'watermelon']}
df = pd.DataFrame(data)
df
# Using regular expressions to find strings containing ‘app’ or ‘an’
filtered_df = df[df[‘Text’].str.contains(r’app|an’)]
filtered_df
Example 2: String Extraction with Regex
# Extracting the numeric portion from strings using regex
df['Number'] = df['Text'].str.extract(r'(\d+)')
df
Example 3: Replacing Substrings with Regex
# Replacing all occurrences of ‘a’ with ‘X’ using regex
df[‘Modified Text’] = df[‘Text’].str.replace(r’a’, ‘X’)
df
These examples demonstrate how regular expressions can be applied in conjunction with Pandas to perform advanced string operations. Regular expressions provide a powerful and flexible approach to pattern matching, extraction, and substitution in string data, allowing you to handle complex string patterns effectively.
Conclusion
In this tutorial, we covered a wide range of topics related to working with string data in Pandas, a powerful data manipulation library in Python. We started by introducing the basics of creating a DataFrame with string data and accessing/modifying string columns. Then, we explored common string operations and methods provided by Pandas, such as concatenation, splitting, stripping, substitution, matching, filtering, case conversion, and computing string length and counts.
We also delved into conditional string operations, where we performed actions based on specific criteria. Additionally, we covered advanced string operations using regular expressions with Pandas. Regular expressions allowed us to handle complex string patterns, perform pattern matching, extraction, and substitution tasks.
Furthermore, we emphasized the importance of string data cleaning and preprocessing. We learned techniques to handle missing values, remove special characters, convert strings to lowercase, and remove stop words. These steps are crucial for ensuring data quality and consistency before further analysis.
Throughout the tutorial, we provided examples that showcased the practical implementation of various concepts. These examples demonstrated how to create a DataFrame with string data, manipulate string columns, perform string operations, implement advanced techniques using regular expressions, and preprocess string data.
By leveraging Pandas’ capabilities for string data manipulation, you now have the necessary tools and knowledge to effectively work with string data in your data analysis projects. Whether it’s extracting insights from textual data, cleaning messy strings, or performing advanced string operations, Pandas offers a rich set of functionalities to handle string data efficiently.
Remember to continue practicing and experimenting with different scenarios to deepen your understanding. With Pandas and its extensive string manipulation capabilities, you can unlock the full potential of your text-based datasets and gain valuable insights for your data analysis endeavors.
Originally published at https://medium.com/ on July 1, 2023.