


Easy and flexible methods to encode categorical variables for further quantitative analysis
In many cases, we need to transfer categorical or string variables into numbers in order to analyze the data quantitatively or develop a model. There are many methods to do that. In this article, I will show you some easy but practical methods to encode columns with categorical data or strings into numerical values.
This article is the Part VII of Data Analysis Series, which includes the following parts. I suggest you read from the first part so that you can better understand the whole process.
- Part I: How to Read Dataset from GitHub and Save it using Pandas
- Part II: Convenient Methods to Rename Columns of Dataset with Pandas in Python
- Part III: Different Methods to Access General Information of A Dataset with Python Pandas
- Part IV: Different Methods to Easily Detect Missing Values in Python
- Part V: Different Methods to Impute Missing Values of Datasets with Python Pandas
- Part VI: Different Methods to Quickly Detect Outliers of Datasets with Python Pandas
- Part VII: Different Methods to Treat Outliers of Datasets with Python Pandas
- Part VIII: Convenient Methods to Encode Categorical Variables in Python
and maybe more.
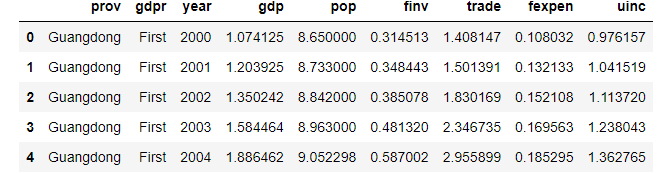
First, let’s read the dataset whose outliers have been treated and saved as gdp_china_outlier_treated.csv in the last part.
# import required packages
import pandas as pd
# read data
df = pd.read_csv('./data/gdp_china_outlier_treated.csv')
# display the first 5 rows
df.head()
1. Factorize methods
Pandas provide a very convenient .factorize method used to factorize a string or more string columns in a pandas DataFrame.
(1) Factorize one column
Suppose we have only one string column, or just factorize one column. First, I will use a copy of the dataset in the example, or the original dataset will be changed. We will still use the original dataset for other methods.
df_copy = df.copy()
df_copy['prov'] = pd.factorize(df_copy['prov'])[0]
df_copy
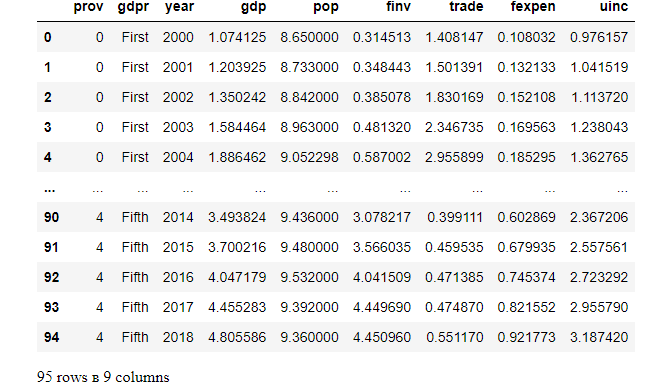
The above table shows that prov column has been factorized.
pd.factorize(df_copy['prov'])[0]
(2) Factorize more columns
In most cases, there are more categorical or string columns in a dataset. In our dataset here, there are two string columns.
df_copy2 = df.copy()
df_copy2[['prov','gdpr']]= df[['prov','gdpr']].apply(lambda x: pd.factorize(x)[0])
df_copy2
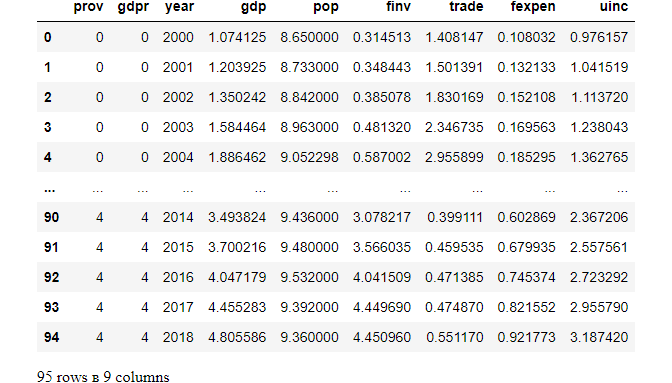
From the above result, we can see the prov and gdpr columns have been factorized.
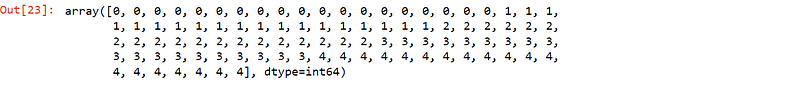
(3) Factorize All Columns
In a few cases, maybe we meet to factorize all columns, and let’s create one such case.
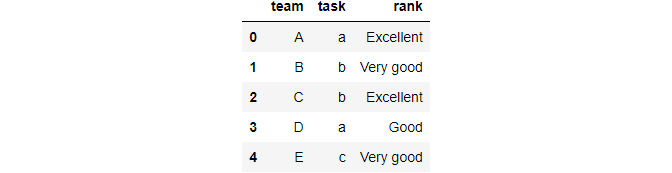
#create DataFrame
df_task = pd.DataFrame({'team': ['A', 'B', 'C', 'D','E'],
'task': ['a', 'b', 'b', 'a','c'],
'rank': ['Excellent','Very good','Excellent','Good', 'Very good'] })
#view DataFrame
df_task
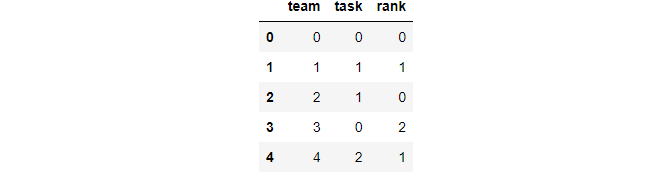
Then you can use the following method.
df_task = df_task.apply(lambda x: pd.factorize(x)[0])
#view updated DataFrame
df_task
2. Replace Methods
In some cases, we perhaps want to start from 1 rather than 0. For example, you think that it is better to encode gdpr (GDP ranking), first to fifth into their number forms 1 to 5 in the dataset in this article. Then you can use replace method.
(1) One columns
df_rep = df.replace(to_replace=['First','Second','Third','Fourth','Fifth'],value=[1,2,3,4,5])
df_rep.head()
(2) More columns
Support we also want to replace with the five provinces with numbers from 0.
numbered = {
"prov": {"Guangdong": 1, "Jiangsu": 2, "Shandong": 3,"Jiangsu": 4,"Henan": 5},
'gdpr':{'First':1, 'Second':2, 'Third':3, 'Fourth':4,'Fifth':5},
}
df_rep2 = df.replace(numbered)
df_rep2
3. Dummy Methods
The get_dummies() method is used to encode string columns.
(1) One column
dum = pd.get_dummies(df['prov'])
dum
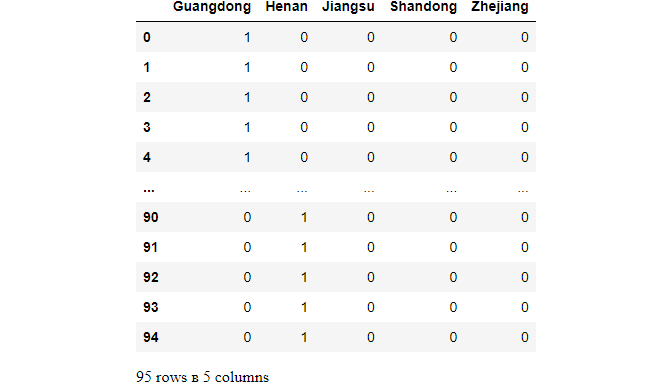
A categorical variable of K categories, or levels, usually enters a regression as a sequence of K-1 dummy variables. Otherwise, it might cause Dummy Variable Trap, where two or more dummy variables created by one-hot encoding are highly correlated (i.e. multi-collinear)
dum = pd.get_dummies(df['prov'], prefix='prov',drop_first=True)
dum
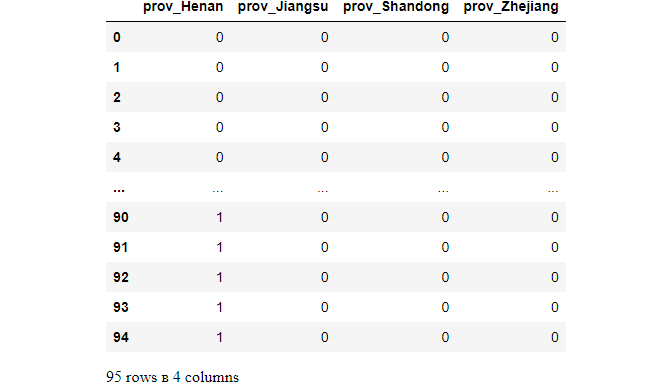
(2) More columns
dums = pd.get_dummies(df[['prov','gdpr']])
dums
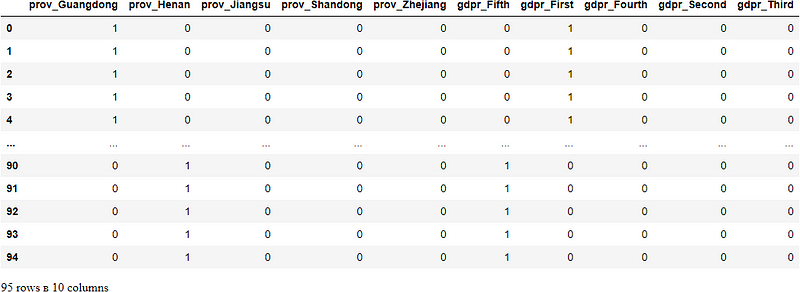
The question here is how to add these dummies to the Dataframe.
(3) Add dummies to Pandas DataFrame
df_coded = df.join(dums)
df_coded
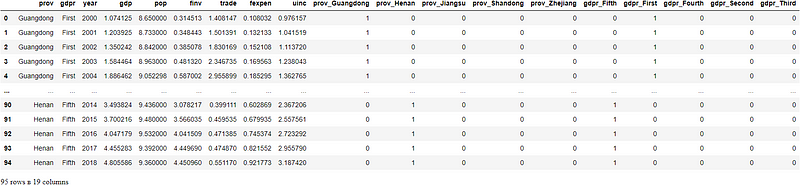
(4) A more compact method
Since pandas version 0.15.0, pd.get_dummies can handle a DataFrame directly, while it could only handle a single Series before that.
df_dum_coded = pd.get_dummies(df)
df_dum_coded
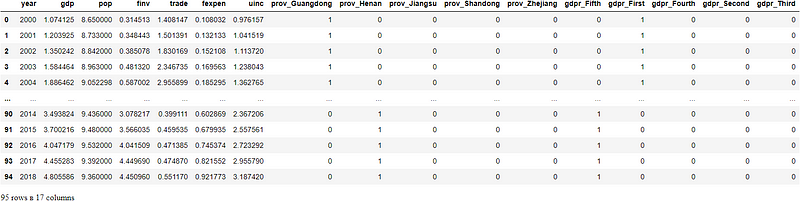
If you want to choose specific dummy columns, you can use the following handy way to specify only one or two columns by their names.
df_selet_dum_coded = pd.get_dummies(data=df, columns=['prov', 'gdpr'])
df_selet_dum_coded
4. OneHotEncoder
The last method that I display here is the OneHotEncoder() function of the scikit-learn library.
(1) remove the gdpr column
The gdpr is actually not helpful for the future data analysis because it is just an alternative label of provinces, thus let’s remove it first. If you do want to keep it, just do it. I use the original Dataframe here since it is the last example.
df.drop(['gdpr'],axis=1, inplace=True)
df.head()

gdpr column has been removed.
(2) import function, define the encoder and fit_transform of string column
from sklearn.preprocessing import OneHotEncoder
# sparse parameter (=True or False): will return a sparse matrix or dense array
# we will not drop the first column of the encoded
enc = OneHotEncoder(sparse=False) # remove first column,set drop='first'
# fit and transform of the prov column
trans = enc.fit_transform(df[['prov']])
(3) show the default names of encoded columns
feature_names = enc.get_feature_names_out(['prov'])
feature_names

We can change the names into abbreviated ones for analysis convenience, especially as modelling variables to develop models in the future.
feature_names = ['prov_gd','prov_hn', 'prov_js', 'prov_sd', 'prov_zj']
feature_names

(4) display them as a Pandas DataFrame
feature_coded = pd.DataFrame(trans, columns=feature_names)
feature_coded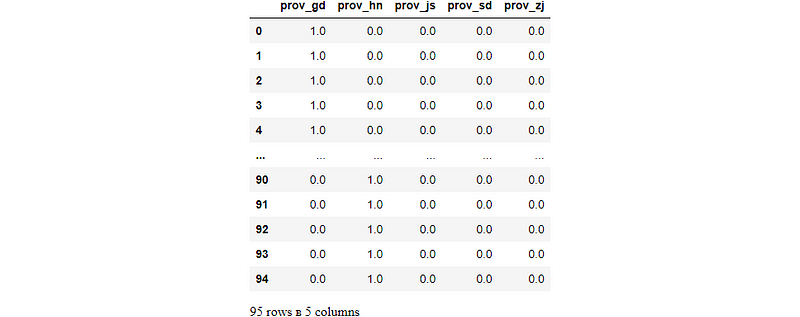
(5) Add it into the original DataFrame
I use concatenate here to combine the encoded columns with the original DataFrame, then drop the prov column since we have encoded it.
df_coded = pd.concat([df,feature_coded],axis=1)
df_coded.drop(['prov'],axis=1, inplace=True)
df_coded
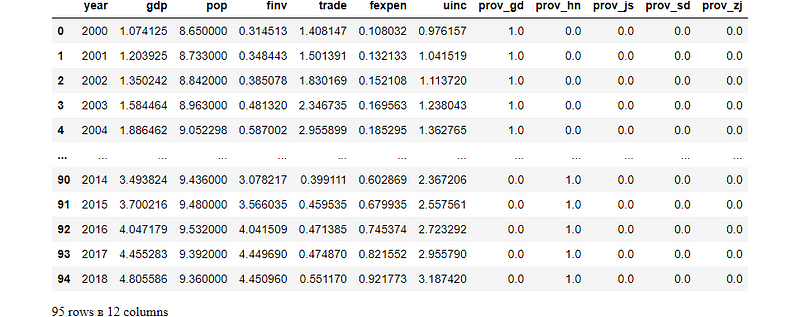
5. Save the Data
Lastly, let’s save the encoded dataset for future analysis use.
df_coded.to_csv('./data/gdp_china_encoded.csv', index=False)6. Online Course
If you are interested in learning Python data analysis in details, you are welcome to enroll one of my course:
Master Python Data Analysis and Modelling Essentials