


To display how easy it is to rename columns of a dataset for different cases using Python Pandas Library
We usually change certain variables, rename, even add or completely replace variable names because the variable names from the original data files don’t adhere to the preferred naming conventions, including but not limited to the following reasons:
- names are very long
- names contains unwanted symbols, special characters or spaces
- names are capitalized, but we need lower cased names, or
- we need to add prefixes or suffixes, and whatever
Thus, we need to change the variable names as an initial step of data management or data analysis. In this post, it displays how to change the variable names, i.e. column names of datasets in the form of Pandas DataFrame.
This article is the Part II of Data Analysis Series, which includes the following parts. I suggest you read from the first part so that you can better understand the whole process.
- Part I: How to Read Dataset from GitHub and Save it using Pandas
- Part II: Convenient Methods to Rename Columns of Dataset with Pandas in Python
- Part III: Different Methods to Access General Information of A Dataset with Python Pandas
- Part IV: Different Methods to Easily Detect Missing Values in Python
- Part V: Different Methods to Impute Missing Values of Datasets with Python Pandas
- Part VI: Different Methods to Quickly Detect Outliers of Datasets with Python Pandas
- Part VII: Different Methods to Treat Outliers of Datasets with Python Pandas
- Part VIII: Convenient Methods to Encode Categorical Variables in Python
1. Load Dataset
In Part I, I have displayed how to read the dataset gdp_china_clean.csv from GitHub into Pandas DataFrame and save it in the working directly of local computer. Now, let’s read the saved dataset into Pandas’ DataFrame directly from the working directory using Pandas’ pd.read_csv() function.
# import the required packages
import pandas as pd
# Read the data
df = pd.read_csv('./data/gdp_china_clean.csv',index_col=0)
# display the first five rows
df.head()
2. Display the column names
Now let’s show the column names only and see what they look like.
df.columns
From the above output, we can see that the names of columns really don’t adhere to the preferred naming conventions for analysis, where names contain spaces, units, long strings, etc. Thus, it is necessary to change them.
3. Rename columns
In this section, we will see different methods to change column names for different situations that we might meet.
3.1 Rename certain columns
In many cases, we need only rename one or two columns because the names of the rest columns meet our preferred naming conventions. For example, suppose we only need to change ‘GDP ranking’ and ‘population (x10⁷ person)’.
In this case, we can use dameframe.rename() function to change ‘GDP ranking‘ to ‘GDP_rank‘ and ‘population (x10^4 person)‘ to ‘POP‘ for instance. In general, there are three different methods.
Method 1:
We use the structure dameframe.rename(columns={'old name1': 'new name1', 'old name2': 'new name2',...}) to rename certain columns.
df_r1 = df.rename(columns={'GDP ranking ': 'GDP_rank', 'population (x10^4 person)': 'POP'})
df_r1.head()
Method 2
The structure of this method is dameframe.rename({'old name1': 'new name1', 'old name2': 'new name2',...}, axis=1). This method is new compared with the first one.
df_r2 = df.rename({'GDP ranking ': 'GDP_rank', 'population (x10^4 person)': 'POP'}, axis=1)
df_r2.head()Method 3
In this method, we just change axis=1 to axis='columns'. In fact, we can also consider methods two and three are the same because axis 1 refers to the columns.
df_r3 = df.rename({'GDP ranking ': 'GDP_rank', 'population (x10^4 person)': 'POP'}, axis='columns')
df_r3.head()3.2 Remove unwanted spaces or symbols from column names
In some cases, we need only rename some columns which contain unwanted spaces or symbols in the names.
(1) Remove unwanted spaces
Python string strip() Method can be used to remove spaces at the beginning and at the end of the string. We use a lamda function to remove unwanted spaces in all column names.
df_r4= df.rename(columns=lambda x: x.strip())
print(df.columns)
print(df_r4.columns)
From the above compared results, we can see that all unwanted spaces have been removed from the column names.
(2) Remove unwanted symbols
We can consider ‘(x10⁸CNY)’ as a symbol or special characters in the column names of ‘total imports and exports (x10⁸CNY)’, and let remove them by using replace() methods to replace it with ''.
df_r5 = df.rename(columns=lambda x: x.replace('(x10^8CNY)',''))
df_r5.columns
3.3 Lowercase or uppercase column names
Sometimes maybe we just rename column by lowercasing or uppercasing their names.
(1) Lowercase column names
df_r6 = df.rename(columns=str.lower)
df_r6.columns
(2) Uppercase column names
For example, we uppercase the column names.
df_r7 = df.rename(columns=str.upper)
df_r7.columns
(2) Lowercase the column names
We can also uppercase or lowercase a whole string column, such as the ‘Province’ column.
df_r8 = df.rename(columns=str.lower)
df_r8.columns

3.4 Rename all columns
In most cases, we want to rename all the columns to short or abbreviated ones, for instance.
(1) use set_axis with a list and inplace=False
new_colnames = ['prov','gdpr','year','gdp','pop','finv','trade','fexpen','uinc']df_r9 = df.set_axis(new_colnames, axis='columns') #default: inplace=False
df_r9.columns
(2) use the .columns attribute with a list
This is a comparatively new method.
df.columns=['prov','gdpr','year','gdp','pop','finv','trade','fexpen','uinc']df.columns
The advantage of using ‘set_axis’ is that it can be used as part of a method chain and that it returns a new copy of the DataFrame, while .columns attribute method will change the original DataFrame.
3.5 Prefix or suffix the column names
In some cases, we need to prefix or suffix the column names. It is very easy to realize it using df.add_prefix()and df.add_suffix() in Pandas. Let’s add china for example because the dataset is about China.
(1) Prefix the column names
df_r10 = df.add_prefix('china_')
df_r10.head()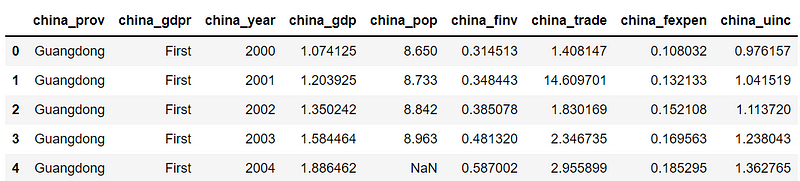
(2) Suffix the column names
df_r11 = df.add_suffix('_china')
df_r11.head()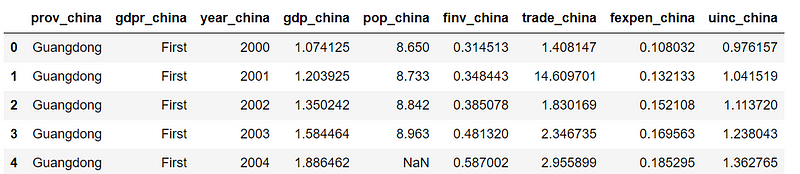
4. Save the new DataFrame
At the end of rename, do not forget to save the modified dataset in your working directory using new data file name, for example, gdp_china_renamed.csv.
df.to_csv('./data/gdp_china_renamed.csv',index=False)5. Online course
If you are interested in learning Python data analysis in details, you are welcome to enroll one of my course:
Master Python Data Analysis and Modelling Essentials