


Normascaler has different data normalization methods including MinMaxScaler, MaxAbsScaler, RobustScaler, StandardScaler, Normalizer, DecimalScaler
In the previous two posts, we have talked about different data normalization methods and its proper process. In those posts, we have discussed that it should split the dataset into training dataset and testing dataset before normalizing them using the same scaler, that is, testing dataset should use the same normalization scaler with training dataset. Besides, it should not normalize the encoded categorical, string or dummy variables. Therefore, it usually cost efforts and times to write codes to normalize dataset when there are encoded categorical, string or dummy variables, even using the built-in normalization scaler functions of scikit-learn.
In addition, decimal scaling method is also very important normalization methods, which makes traditional statistic linear model much easier and more meaningful to explain. However, I have not found a package including decimal scaling normalization. This method seem easy, but it will cost time to write code to calculate the scaler for each variable when there are many variables.
Based on these reasons, I have created a normalization package to deal with above issues. The package is named as normscaler, standing for normalization scalers, which has been used by myself for a couple of years, but was just published publicly before I wrote this post.
You can find it on the PyPI page and in my GitHub depository, where you can also find detailed information and example. In this post, I will display how to install and use this package.
1. Install the Package
It can be easily installed from PyPi using
pip install normscaler
The installing process looks as follows:
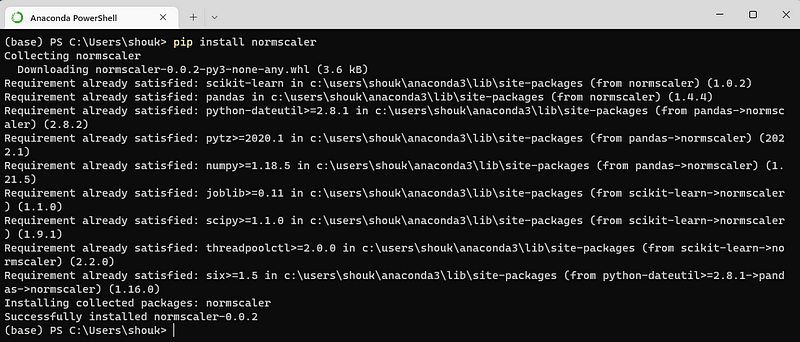
2. Convenience of the Package
This package has two dependencies, Pandas and Scikit-learn, and it uses Pandas DataFrame as its dataset form and the built-in normalized scalers of Scikit-learn. It will automatically install them if you have not installed them.
Comparing with other packages, this package have the following conveniences:
(1) It includes all the widely-used normalization methods. Besides the normalization scalers in Scikit-learn, it also includes Decimal scaling method, i.e. DecimalScaler.
- MinMaxScaler
- MaxAbsScaler
- RobustScaler
- StandardScaler
- Normalizer
- DecimalScaler
(2) It can easily import the normalization scaler by just their names, for example:
from normascaler.scaler import DecimalScaler
(3) There are two parameters:
X_train_scaled, X_test_scaled = DecimalScaler(X_train, X_test)
Parameters:
X_train: the split data for model training/estimation
X_test: the split data for model testing/validation
Return:
X_train_scaled: the normalized training dataset in Pandas DataFrame
X_test_scaled: the normalized testing dataset in Pandas DataFrame
(4) It will skip the one-hot encoded variables, and they will not be normalized. It is widely accepted that the encoded string, categorical or dummy variables should not be normalized. You have to use one-hot encode methods, such as the get_dummies( ) method in Pandas or OneHotEncoder() in Scikit-learn, to encode your string, categorical or dummy variables to use this function of the package.
3. An Example
In this example, we will use DecimalScaler and MinMaxScaler to show how to use this package for data normalization with one-hot encoded variables.
(1) Import required packages
import pandas as pd
from sklearn.model_selection import train_test_split
from normscaler.scaler import DecimalScaler,MinMaxScaler
(2) Read the dataset
url = ‘https://raw.githubusercontent.com/shoukewei/data/main/data-pydm/gdp_china_encoded.csv'
df = pd.read_csv(url)
df
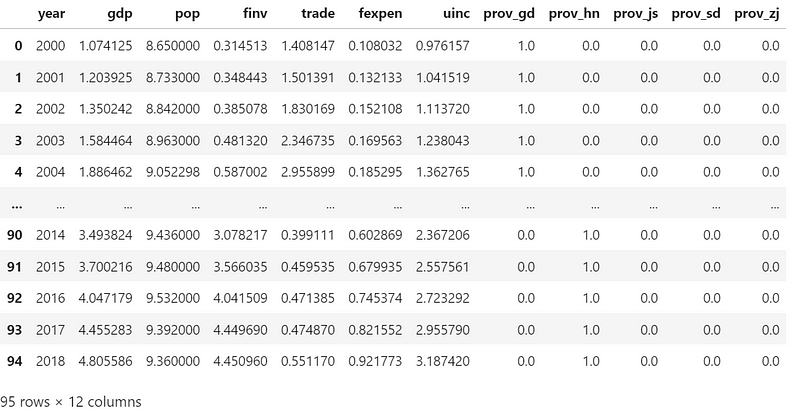
(3) Slice data into features X and target y
GDP is the target and others are features.
X = df.drop(['gdp'],axis=1)
y = df['gdp']
(4) Split dataset for model training and testing
Split the dataset for model training/estimation and testing/validation.
X_train, X_test, y_train, y_test = train_test_split(X, y,test_size=0.30, random_state=1)
Display dataset for trainig.
X_train
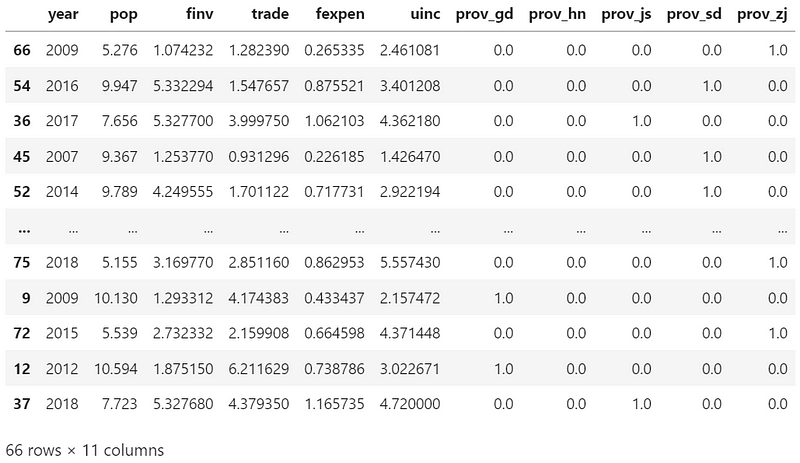
Display dataset for testing.
X_test
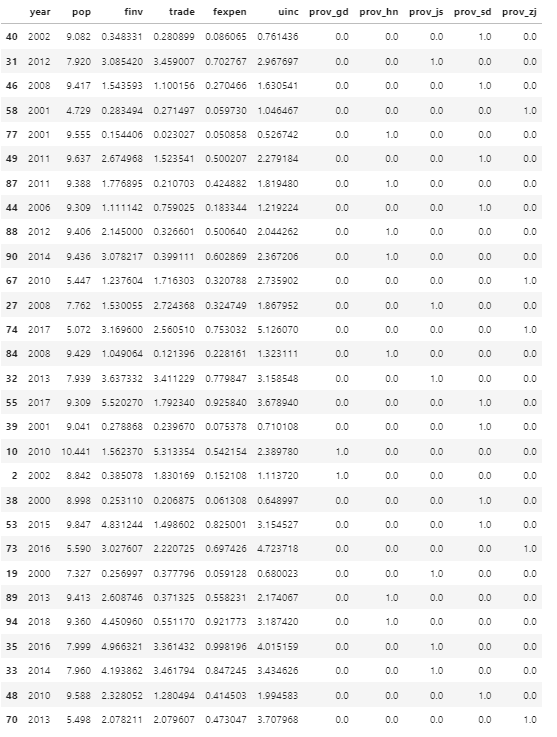
(5) Data Normalization with Decimal scaling method
First, let’s see the example using DecimalScaler, which should be imported first. We have already imported it in section (1). Here, let’s name the normalized dataset as X_train_scaled and X_test_scaled. You can use other names you like.
X_train_scaled, X_test_scaled = DecimalScaler(X_train,X_test)
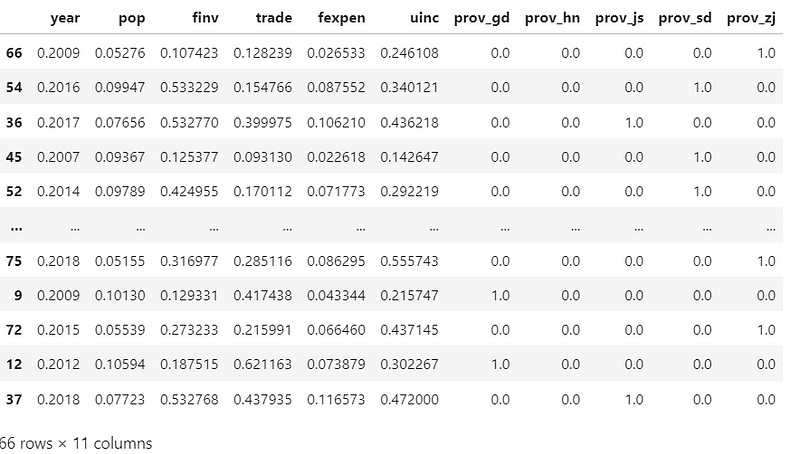
Display the normalized train dataset in Pandas DataFrame.
X_train_scaled
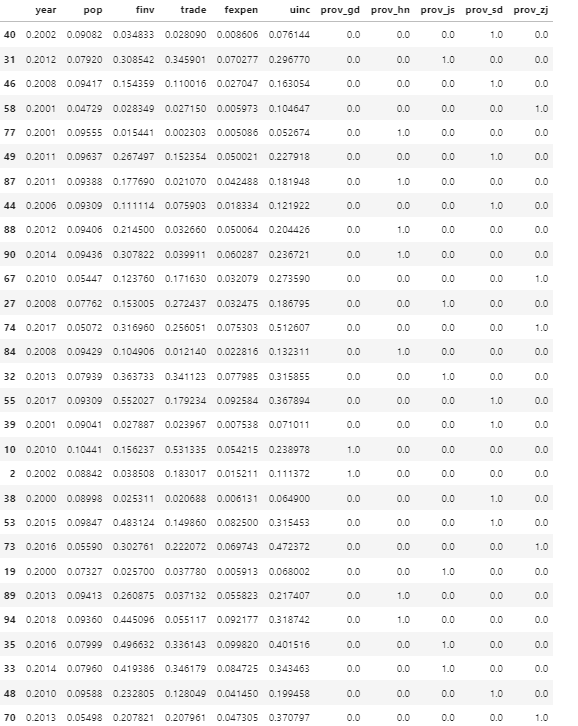
Display the normalized test dataset in Pandas DataFrame.
X_test_scaled
(6) Data Normalization with MinMaxScaler
Let’s see another example using MinMaxScaler, which should be imported first. We have already imported it in section (1).
X_train_scaled, X_test_scaled = MinMaxScaler(X_train,X_test)
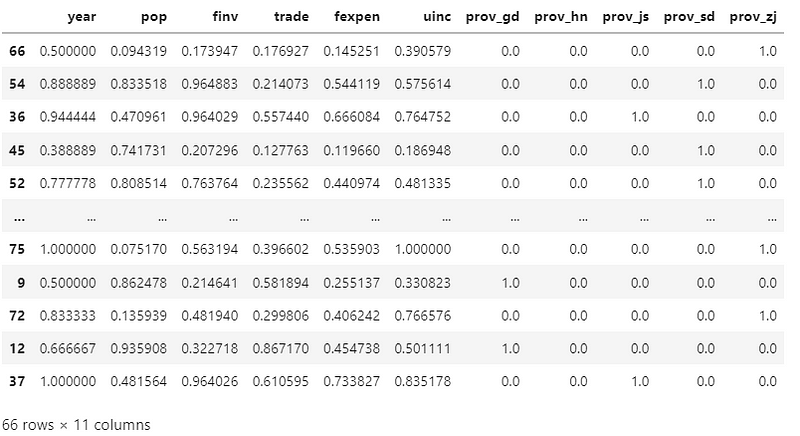
Display the normalized train dataset in Pandas DataFrame.
X_train_scaled
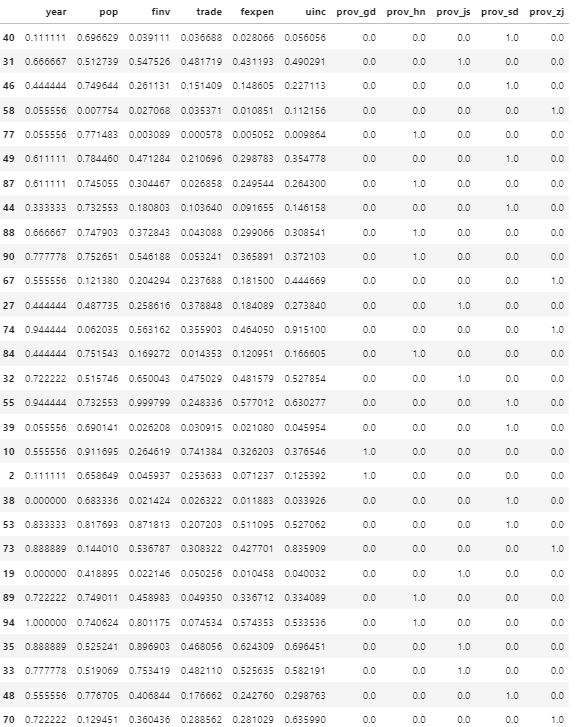
Display the normalized test dataset in Pandas DataFrame.
X_test_scaled
Online Course
If you are interested in learning Python data analysis in details, you are welcome to enroll one of my courses:
Master Python Data Analysis and Modelling Essentials