


This article will display how to easily speed up Pandas’ code by just changing a single line of code with Python Modin library using a real-world example.
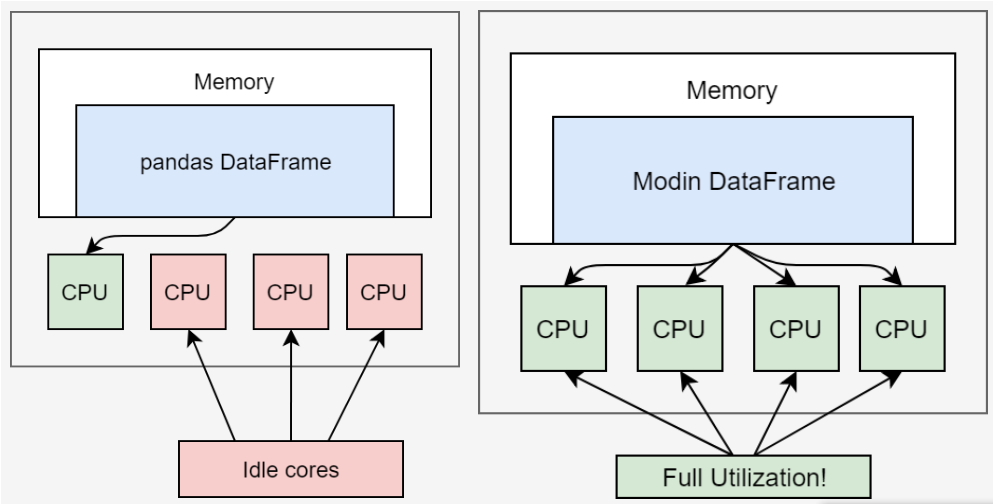
Pandas is probably the most popular open-source library for data computation and analysis in Python due to its easy to use DataFrame data format. However, Pandas was not originally designed for big data. The major limitations of Pandas are that it uses only one single CPU core at a time, and it does not support multi-threading, parallel and distributed computations. Thus, the execution speed will deteriorate when dataset becomes larger, and it may run out of memory while processing big data. I believe you have experience this issue when you practice the examples in my previous article.
Fortunately, there are many libraries developed to support big data processing, such as Modin, Dask, CuDF, Ray, Vaex, Polars, etc. From this article, we start to touch the topic of big data analysis from Modin. Modin is an open source library developed by Devin Petersohn in the RISELab at UC Berkeley, which aims to speed up manipulation and analysis for all dataframes from 1 MB To 1 TB+. We start from Modin, becuase it is probably the most easiest one, and it need not any distributive computing knowledge. It is a drop-in replacement for Pandas with the same syntax with it, and it is fully compatible with Pandas. What you need is just changing one line, i.e. the import statement, and then you can still continue using the existing pandas code.
Modin uses Ray or Dask libraries in backend to perform parallel and distributed computations efficiently by adopting a DataFrame partitioning method which enables splits along both rows and columns. Comparing to Pandas, it enables to use all the available CPU cores, and it is capable of speeding up your pandas scripts up to 4x.
The last article is prerequisite to this article, and there are also some overlap between this article and last one. You’d better glance over the last article before starting to read the following section, because we will use the method introduced and the dataset downloaded in the last article. Otherwise, you will feel confused about this article. In this article, we will see how to use Modin to speedup Pandas’ code using the dataset of 1.92 GB with 22,519,712 rows.