


Machine learning, modelling, and data analysis all need suitable datasets to test the algorithms
I still clearly remember that when I pursued my PhD in Germany18 years ago, my Professor said, “… Keine Daten, Keine Modellierung …” (which means ‘no data, no modelling’ in English) in his statistic modelling class. Collecting a suitable dataset to develop a model and test an algorithm is challenging.
In two of my previous posts, I discussed how to read dataset from GitHub and read dataset from Google Drive. GitHub is an Internet hosting service for software development, but meaning while there are many datasets in its repositories. Google Drive is not a data source, but it is a convenient place to store our data.
Besides, Kaggle is a good source for dataset. According to Kaggle, there are over 50,000 public datasets with a new uploaded dataset every day on Kaggle. In this post, we will talk about two methods that can be used to easily search and download datasets from Kaggle inside Jupyter notebook. And then you can read it conveniently for your analysis or training your model. You can use any IDEs or Terminal, although I say using Jupyter notebook.
1. Install kaggle CLI
First, we need to install kaggle CLI to access the Kaggle API. Just type the folowing command.
pip install kaggle
The last few lines of installation looks as follows:
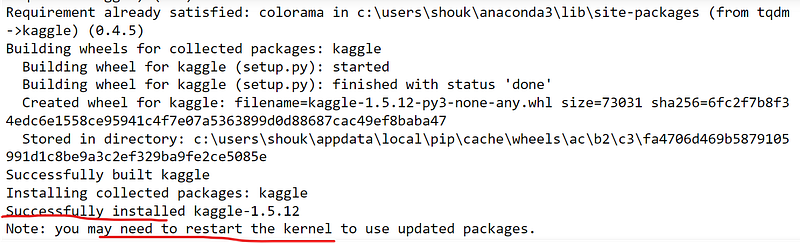
It shows that kaggle was successfully installed, and you also may need to restart the kernel of Jupyter notebook.
2. Get the API token
You need to register an account, which is very easy and we will not talk about here. To use the Kaggle’s public API, you must first authenticate using an API token, which can be obtained from your account.
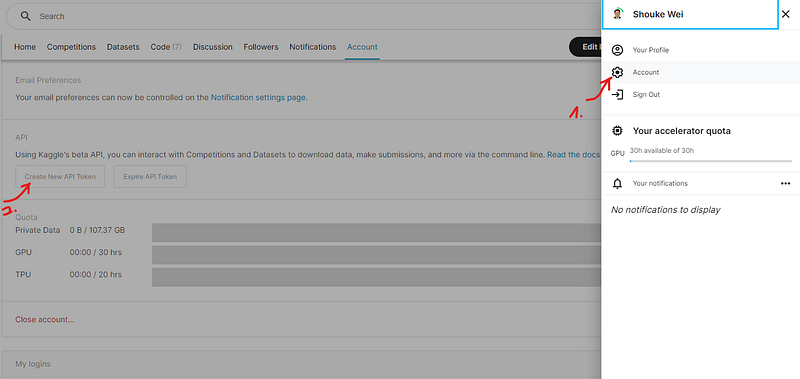
From your account, just click the picture header on the right-top corner. Then click account, scroll down to API. Click Create New API Token’, a file named kaggle.json will be downloaded in your computer.
3. Methods
In the following, I introduce 2 methods, from which you can choose one you like.
Step 1: choose one method
Method 1: Put API in the .kaggle folder
The easy way to find where the downloaded API token should be put in. Just type the following in Jupyter code cell or in Terminal:
import kaggle
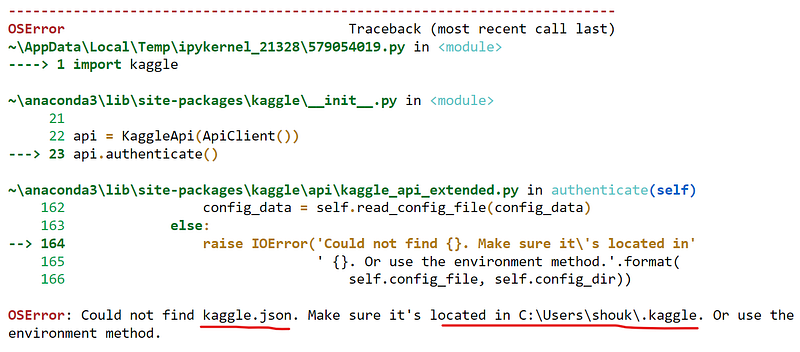
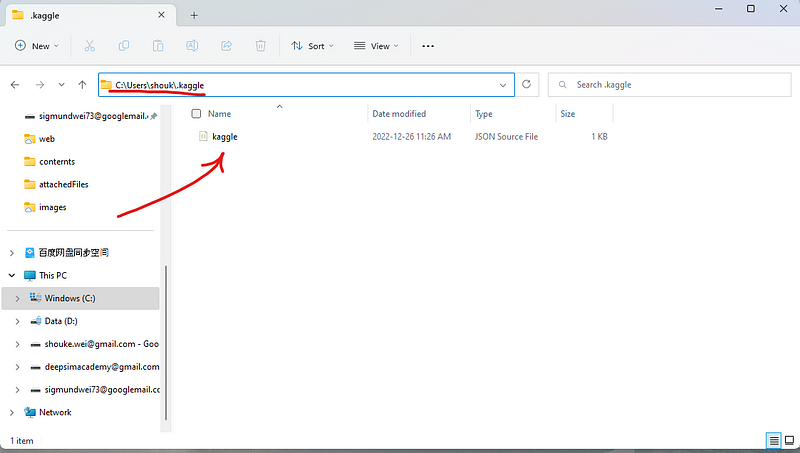
The above error message indicates that where we should put downloaded kaggle.json in, for example, C:\Users\shouk\.kaggle for my case of using Windows. Just open the folder, and copy the kaggle.jsoninside it.
Method 2: Run a code snippet including API token
In this method, you do not need to put klagge.json in the .klagge folder. But you have to write a simple code snippet in a code cell of Jupyter notebook as follows.
import os os.environ['KAGGLE_USERNAME'] = "ursername" os.environ['KAGGLE_KEY'] = "Key"
First, you need to open the klagge.json file, and copy the username in file and paste it to replace the username in the code. Similarly, you copy your key from the file and paste it to the place of key in the code. After finishing, just run the code to go on the next step.
Step 2: Change directory
Change the directory to the folder, where you want to save the downloaded data in. Or the data will download into the main folder of your working directory. For me, I usually create a data folder inside the working directory. So I change the path to it.
cd ./data
Step 3: Search the dataset
For example, we are searching world economics dataset. In Jupyter notebook, we have to put ! before kaggle, or there will be an error. You can put quotations around the data name, like ‘economics’ or just type the name without them.
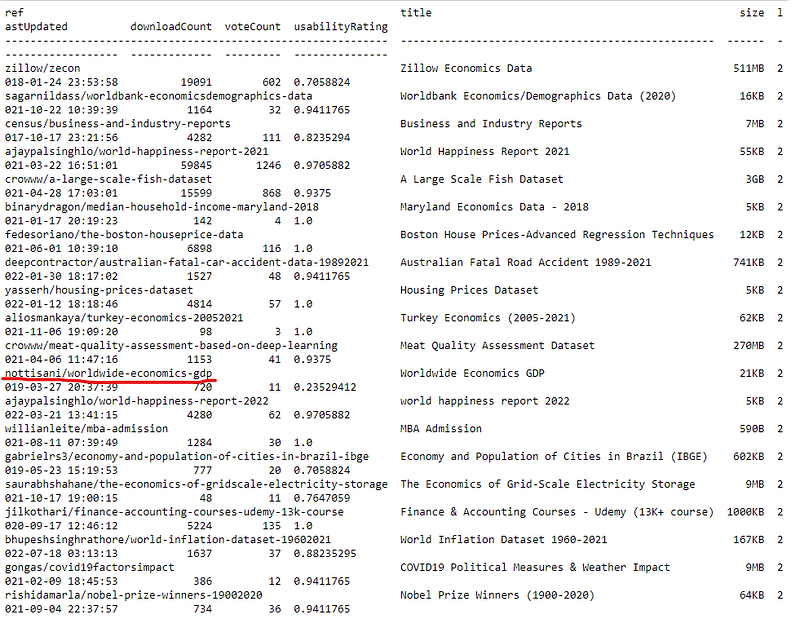
!kaggle datasets list -s economics
After running the code, we will get a list as follows:
Step 4: Download the dataset
Suppose we want to download the nottisani/worldwide-economics-gdp. Here, we cannot add quotations around this name, or there will be an error, like 403 forbidden.
!kaggle datasets download -d nottisani/worldwide-economics-gdp
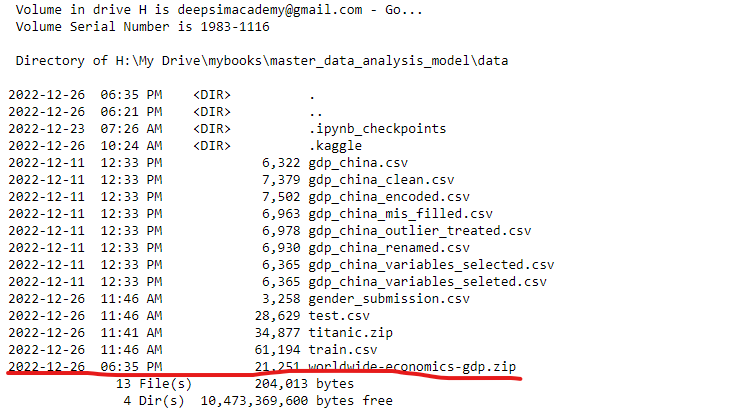
After running the command, the zipped dataset was download into the data folder.

You can check it by:
%ls
Step 5: Unzip it
Let’s unzip dataset file so that it can read easily in Python, such as Pandas. There are different methods, and I like the following way. It needs zipfile package, and you have to install it first. For Anaconda, it should be preinstalled.
import zipfile as zf
files = zf.ZipFile("worldwide-economics-gdp.zip",'r')
files.extractall()
files.close()Enjoy!