


Sort dataset in ascending or descending sort order using a real-world dataset
This article will display how to sort DataFrame with Pandas using a real-world dataset, gdp_china_renamed.csv, which is the dataset saved after renaming the columns with different methods in one previous article. If you have followed the examples in that article and saved the dataset in your working directory, just go ahead to use it in the following sections.
If not, you can download the dataset from my GitHub by clicking this link. I suggest you reading the article on how to read the dataset directly from GitHub if you are read my post the first time, or you are not familiar of that.
Now, let’s read the data into Pandas’ DataFrame.
# Load the required packages
import pandas as pd
# Read the data
df = pd.read_csv('./data/gdp_china_renamed.csv')
# diplay the first 5 rows
df.head()
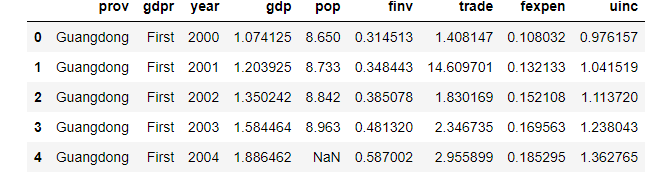
1. Sort the data by one column
The default sorting method is ascending, i.e. ascending=True. Here, suppose we sort the data based on gdp value use in descending, i.e.ascending=False.
df.sort_values(by=['gdp'],ascending=False)
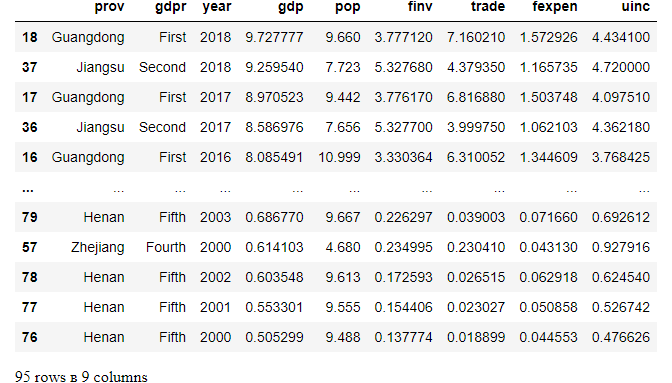
We can omit the by=.
df.sort_values(['gdp'],ascending=False)
2. Sort the data by 2 or more columns
We can sort the dataset based on 2 columns, for example.
df.sort_values(by=['year','gdp'],ascending=[False,True])
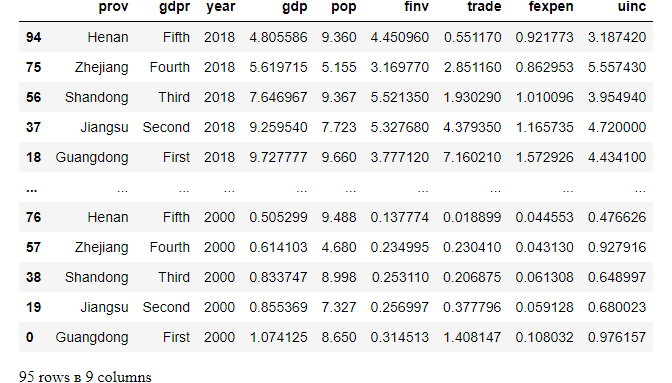
3. Sort the Data with NAs
We have found there are two missing values in popcolumn through the analysis with different methods in a previous article. We use theinfo() method to display the dataset information here again, and we can see that pop has only 93 non-null values, i.e 2 missing values.
df.info()

df.sort_values(by=['pop'],na_position='first')
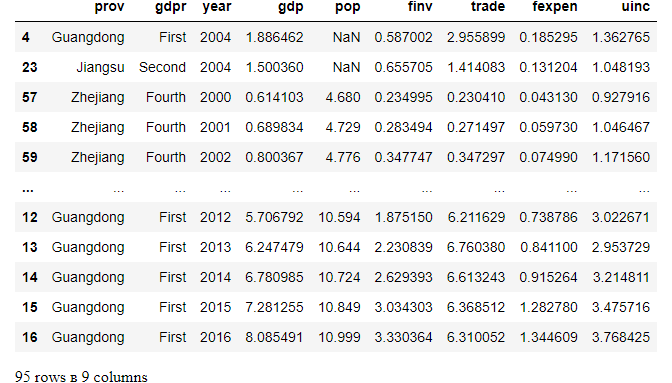
From the above output, we can see that the missing values are listed in the front.
4. Online course
If you are interested in learning data analysis in details, you are welcome to enroll one of my courses:
Master Python Data Analysis and Modelling Essentials