


Demonstrate how to easily add columns in a DateFrame of Pandas
As we know, Pandas is a popular Python library used for data manipulation and analysis. In the last article, it has displayed 4 convenient methods to add new rows in a Pandas DataFrame. Another part of the story is how to add new columns in a Pandas DataFrame.
Pandas offers a variety of methods to add columns to a DataFrame, and this article will introduce several practical methods, including assigning a scalar value, applying a function, or merging data from other sources. In this tutorial, we will explore these methods using real-world data.
Importing the Data
Before we begin, let’s import some data to work with. We will still use the “Iris” dataset, which contains information about different types of iris flowers. To import the dataset, we will use the following code:
In [1]:
import pandas as pd url = 'https://archive.ics.uci.edu/ml/machine-learning-databases/iris/iris.data' cols = ['sepal_length', 'sepal_width', 'petal_length', 'petal_width', 'class'] df = pd.read_csv(url, header=None, names=cols) df.head()
Out[1]:
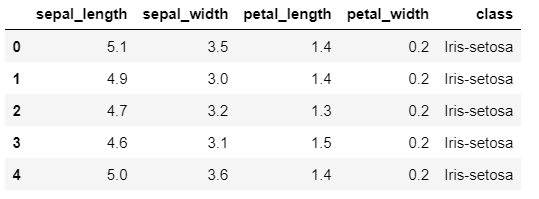
This code imports the dataset from a URL, sets the column names, and creates a DataFrame called “df” to store the data.
Method 1: Assigning a Scalar Value
The first method to add a column to a DataFrame is to assign a scalar value. This is useful when we want to add a column with the same value for every row. For example, let’s say we want to add a column called “species_code” that assigns a numeric code to each species of iris. We can do this using the following code:
In [2]:
df1 = df.copy()
df1['species_code'] = df1['class'].map({'Iris-setosa': 0, 'Iris-versicolor': 1, 'Iris-virginica': 2})
df1.head()Out[2]:
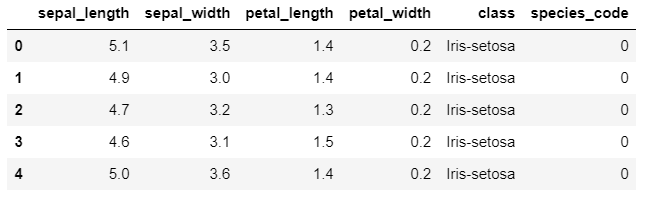
This code creates a new column called “species_code” and assigns a numeric code to each species of iris using the map() method. The resulting DataFrame should look like this:
Method 2: Assigning a Calculation
We can use the syntax df["new_column_name"] = ... to create a new column, for example called “sepal_area” in the DataFrame iris. The calculation to populate the new column is the product of the “sepal_length” and “sepal_width” columns.
In [3]:
df2 = df.copy()
df2["sepal_area"] = df2["sepal_length"] * df2["sepal_width"]
df2.head() Out[3]:
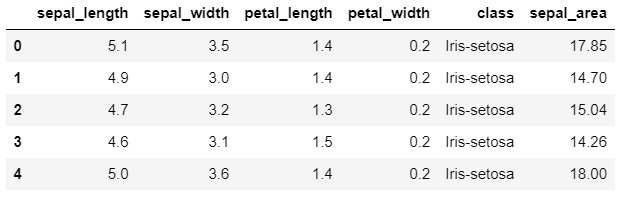
Method 3: Applying a Function
The third method to add a column to a DataFrame is to apply a function. This is useful when we want to add a column that is calculated based on values from other columns. For example, let’s say we want to add a column called “petal_area” that calculates the area of each iris petal. We can do this using the following code:
In [4]:
df3 = df.copy()
def calculate_petal_area(row):
return row['petal_length'] * row['petal_width']
df3['petal_area'] = df3.apply(calculate_petal_area, axis=1)
df3.head()Out[4]:
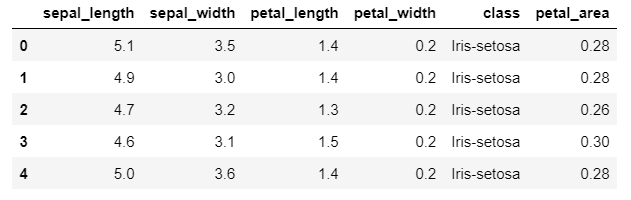
This code defines a function called calculate_petal_area() that takes a row of data as input and calculates the petal area based on the petal length and width. The apply() method is then used to apply this function to each row of the DataFrame, creating a new column called “petal_area”.
Method 4: Merging Data from Other Sources
The fourth method to add a column to a DataFrame is to merge data from other sources. This is useful when we have additional information about the data that we want to add to the DataFrame. For example, let’s say we have a separate dataset that contains information about the country of origin for each species of iris. We can merge this information with our existing DataFrame using the following code:
In [5]:
df4 = df.copy()
country_data = {'Iris-setosa': 'USA', 'Iris-versicolor': 'Canada', 'Iris-virginica': 'Brazil'}
country_df = pd.DataFrame.from_dict(country_data, orient='index', columns=['country'])
df4 = df4.join(country_df, on='class')
df4.head()Out[5]:
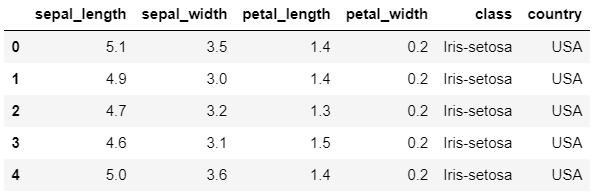
This code creates a dictionary called country_data that maps each species of iris to its country of origin. We then create a DataFrame called country_df from this dictionary and merge it with our existing DataFrame using the join() method. The on parameter specifies that the join should be based on the “class” column.
Method 5: Creating a New Column using .loc
We can also create a new column called “sepal_area” that calculates the area of each flower’s sepal using .loc.
In [6]:
df5 = df.copy() df5.loc[:, 'sepal_area'] = df5.loc[:, 'sepal_length'] * df5.loc[:, 'sepal_width'] df5.head()
Out[6]:
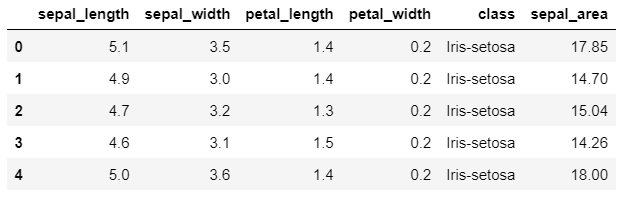
Here, we’re using loc to select all rows (denoted by the :), and the ‘sepal_area’ column. We’re then assigning the product of the ‘sepal_length’ and ‘sepal_width’ columns to this new column.
Method 6: Add Columns at a Specific Index
Let’s add the new column called “sepal_area” that calculates the area of each flower’s sepal, but this time we’ll add it at index 2. Here, we’re using the insert() method to insert the new column ‘sepal_area’ at index 2. The first argument to insert() is the index where the column should be inserted, and the second argument is the name of the new column. The third argument specifies the calculation we want to perform to populate the new column.
In [7]:
df6 = df.copy() df6.insert(2, 'sepal_area', df5['sepal_length'] * df6['sepal_width']) df6.head()
Out[7]:
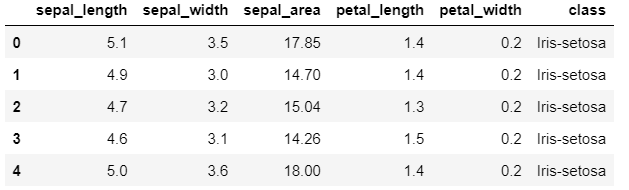
As you can see, the new column ‘sepal_area’ has been added to the DataFrame at index 2 with the correct values. Note that you can use insert() to add columns at any position in the DataFrame, and you can also specify multiple columns to be added at once.
Method 7: Creating Columns using assign () Method
Columns can also be created using the assign() method, which returns a new DataFrame with the added columns, without modifying the original DataFrame.
Let’s create the column called “sepal_area” that calculates the area of each flower’s sepal:
In [8]:
iris_with_area = df.assign(sepal_area=df['sepal_length'] * df['sepal_width']) iris_with_area.head()
Out[8]:
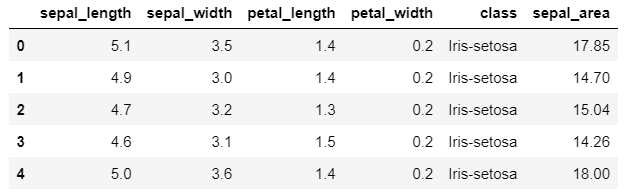
Here, we’re using the assign() method to add the new column ‘sepal_area’ to the DataFrame df. The first argument to assign() is the name of the new column, and the second argument specifies the calculation we want to perform to populate the new column.
Note that the original DataFrame df is not modified. Instead, assign() returns a new DataFrame called iris_with_area that includes the added column.
Conclusions
In conclusion, there are several ways to add columns to a pandas DataFrame, each with its own advantages and use cases.
The insert() method can be used to add a new column at a specific index, which can be useful if you need to insert a column in the middle of your DataFrame. The assign() method can be used to add virtual columns to your DataFrame, which are not physically added to the DataFrame but are returned as part of a new DataFrame. This can be useful for experimenting with new columns without altering your original data. The loc[] method can be used to add a new column by assigning values to a specific slice of the DataFrame, which can be useful if you need to add a column based on specific conditions. Finally, the simplest way to add a new column to a pandas DataFrame is to use the syntax df["new_column_name"] = .... This is a quick and easy way to add a new column, but it can be less flexible than the other methods.
Overall, it’s important to choose the method that best fits your specific use case and take into account factors such as performance, flexibility, and ease of use.