


To display how to easily add new rows to the beginning, end and any other position of a DataFrame in Pandas
Pandas is a popular Python library used for data manipulation and analysis. It provides many functionalities to add, manipulate, and transform data, which we have discussed in many previous articles. Some of my students asked me how to add new rows in the data, so I decide to write this tutorial article.
There are different methods that we can use to add new rows in the data. Before we dive into the different methods, let’s first create a sample DateFrame using a real-world data. We will use the “iris” dataset, which is a popular dataset used for classification and clustering. The dataset contains 150 observations of iris flowers, each with four features (sepal length, sepal width, petal length, and petal width) and a target variable (species).
1. Load the dataset
To load the dataset, we can use the following code:
In [1]
import pandas as pd
iris = pd.read_csv("https://archive.ics.uci.edu/ml/machine-learning-databases/iris/iris.data",
header=None,
names=['sepal_length', 'sepal_width', 'petal_length', 'petal_width', 'species'])
iris.head()Out [1]:
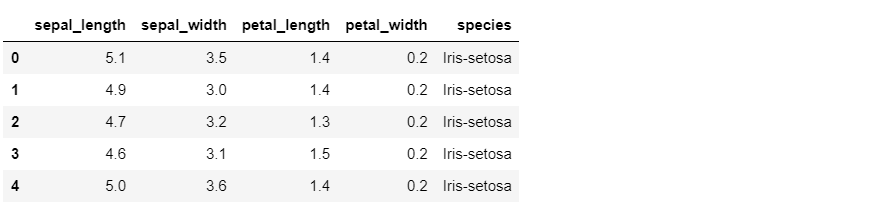
This will create a DataFrame “iris” with five columns: sepal_length, sepal_width, petal_length, petal_width, and species.
Now, let’s discuss the different methods to add rows to this dataframe.
2. Add rows at the end
First, let’s see how to add new rows at the end of the Dataframe. We will repeatedly use a copy of the original data to display the methods in order not to change the original one.
Method 1: Using .loc
The .loc[] method in pandas is used to access a group of rows and columns by label(s) or a boolean array. We can use this method to add a new row to the DataFrame. For example, to add a new row with values (5.1, 3.5, 1.4, 0.2, ‘setosa’), we can use the following code:
In [2]:
iris1 = iris.copy()
iris1.loc[len(iris)] = [5.1, 3.5, 1.4, 0.2, 'setosa']
iris1.tail()Out [2]:
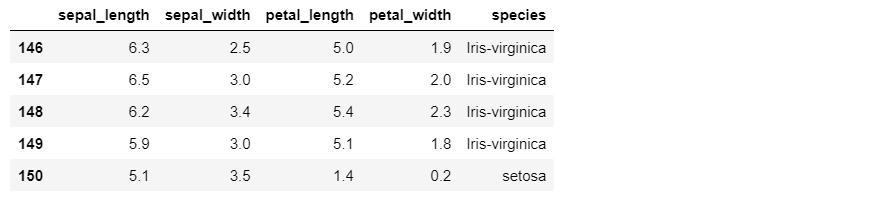
Here, len(iris) returns the length of the dataframe, which is 150. The new row is added to the end of the dataframe.
Method 2: Using .append()
The .append() method in pandas is used to append rows of other DataFrame to the end of the given DataFrame, returning a new DataFrame object. We can create a new DataFrame with the row we want to add, and then append it to the original DataFrame. For example, to add a new row with values (5.1, 3.5, 1.4, 0.2, ‘setosa’), we can use the following code:
In [3]:
iris2 = iris.copy()
new_row = pd.DataFrame({'sepal_length': [5.1], 'sepal_width': [3.5], 'petal_length': [1.4], 'petal_width': [0.2], 'species': ['setosa']})
iris2 = iris.append(new_row, ignore_index=True)
iris2.tail()
Out [3]:
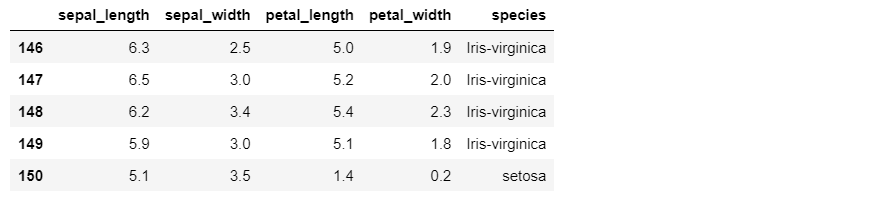
However, the futurewarning message shows that this method will be deprecated.
Method 3: Using .concat()
The .concat() method in pandas is used to concatenate two DataFrame along a particular axis. We can create a new DataFrame with the row we want to add, and then concatenate it with the original DataFrame along the row axis. For example, to add a new row with values (5.1, 3.5, 1.4, 0.2, ‘setosa’), we can use the following code:
In [4]:
iris3 = iris.copy()
new_row = pd.DataFrame({'sepal_length': [5.1], 'sepal_width': [3.5], 'petal_length': [1.4], 'petal_width': [0.2], 'species': ['setosa']})
iris3 = pd.concat([iris3, new_row], ignore_index=True)
iris3.tail()Out [4]:
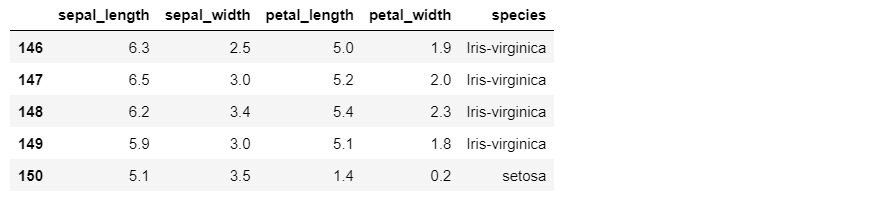
Here, we create a new DataFrame “new_row” with the values we want to add. Then, we use the .concat() method to concatenate this DataFrame with the original “iris” DataFrame along the row axis (axis=0). The “ignore_index=True” parameter is used to reset the index of the resulting DataFrame.
3. Add Rows at the Beginning
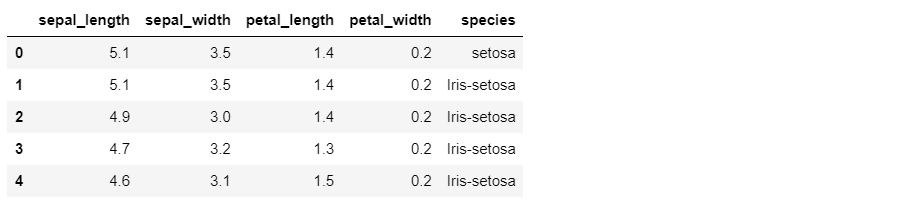
To add a new row to the beginning of a pandas DataFrame, we can use the .loc[] method and specify the index value as 0. Here’s an example:
In [5]:
iris4 = iris.copy()
new_row = pd.DataFrame({'sepal_length': [5.1], 'sepal_width': [3.5], 'petal_length': [1.4], 'petal_width': [0.2], 'species': ['setosa']})
iris4 = pd.concat([new_row, iris], ignore_index=True)
iris4.head()Out [5]:
4. Add Rows at any other position
To add a new row at any other position in a pandas dataframe, we can use the .iloc[] method to insert the row at a specific index location. Here’s an example:
In [6]:
iris5 = iris.copy()
new_row = pd.DataFrame({'sepal_length': [5.1], 'sepal_width': [3.5], 'petal_length': [1.4], 'petal_width': [0.2], 'species': ['setosa']})
iris5 = pd.concat([iris.iloc[:2], new_row, iris.iloc[2:]], ignore_index=True)
iris5Out [6]:
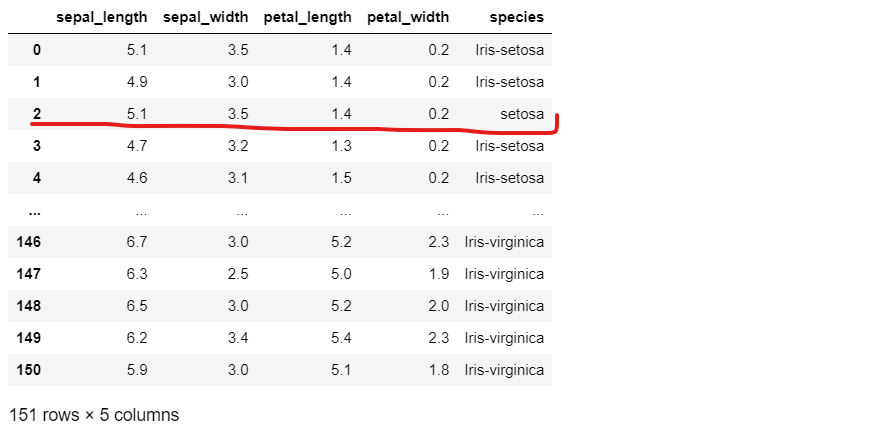
Here, we create a new DataFrame “new_row” with the values we want to add. Then, we use the .iloc[] method to split the original “iris” DataFrame into two parts – the first two rows and the remaining rows (from index 2 onwards). We concatenate the first part, the new row, and the second part using the .concat() method, and specify “ignore_index=True” to reset the index of the resulting DataFrame. By changing the index values in the .iloc[] method, we can insert the new row at any desired position.
5. Conclusions
Adding rows to a pandas a DataFramee is a common task in data analysis and manipulation. There are three common methods to add new rows to a pandas DataFrame with real-world data – appending a dictionary or list to the DataFrame, using the .loc[] method to add a new row by index label, and using the .concat() method to concatenate a new row with the existing DataFrame along the row axis. Each method has its advantages and disadvantages, and choosing the right method depends on the specific use case.
In addition, we also discussed how to add a new row to the beginning of a pandas DataFrame using the .loc[] method and specifying the index value as 0, and how to add a new row at any other position using the .iloc[] method to insert the row at a specific index location.
Overall, adding rows to a pandas DataFrame is a straightforward process with multiple methods to achieve the desired result. It is important to understand the different methods and their use cases in order to make the most efficient use of pandas for data manipulation.